Hadoop部署实验报告
本文最后更新于 2026年6月15日 下午
set java home
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk运行map reduce
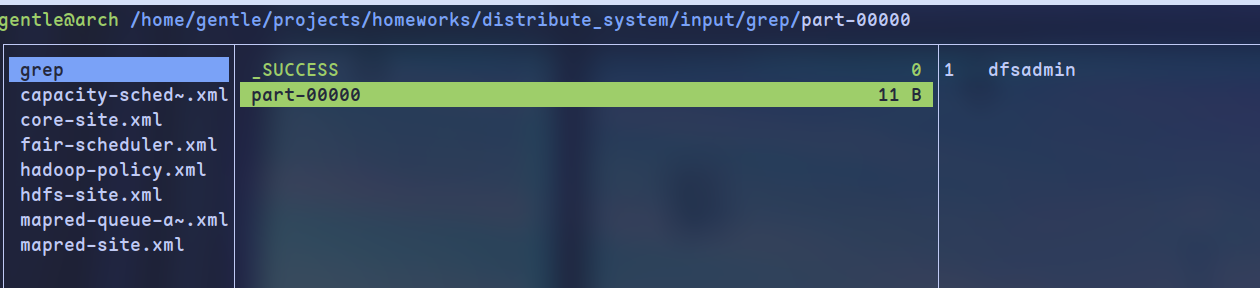
运行word count
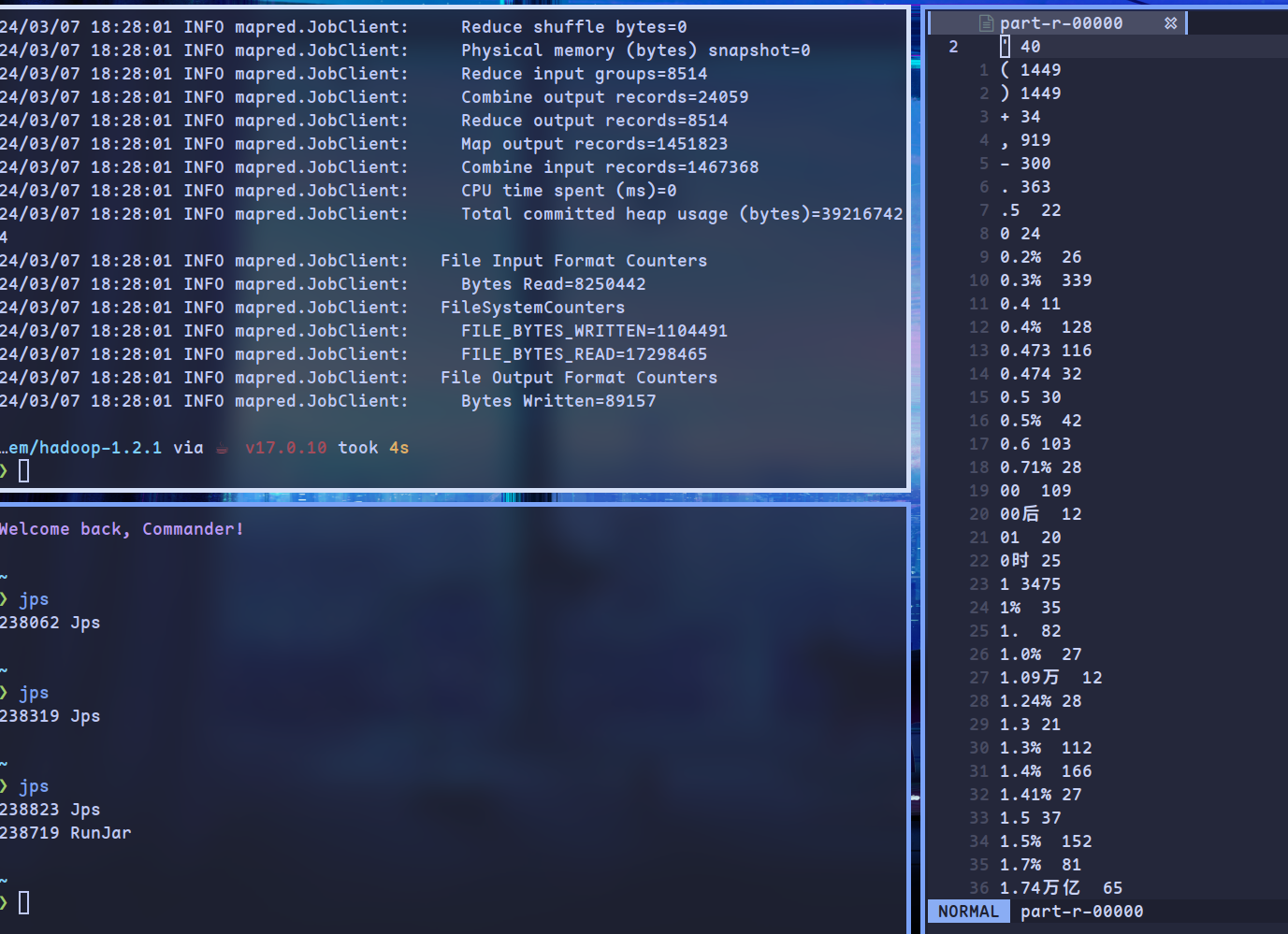
启动hdfs


hdfs shell
目录操作
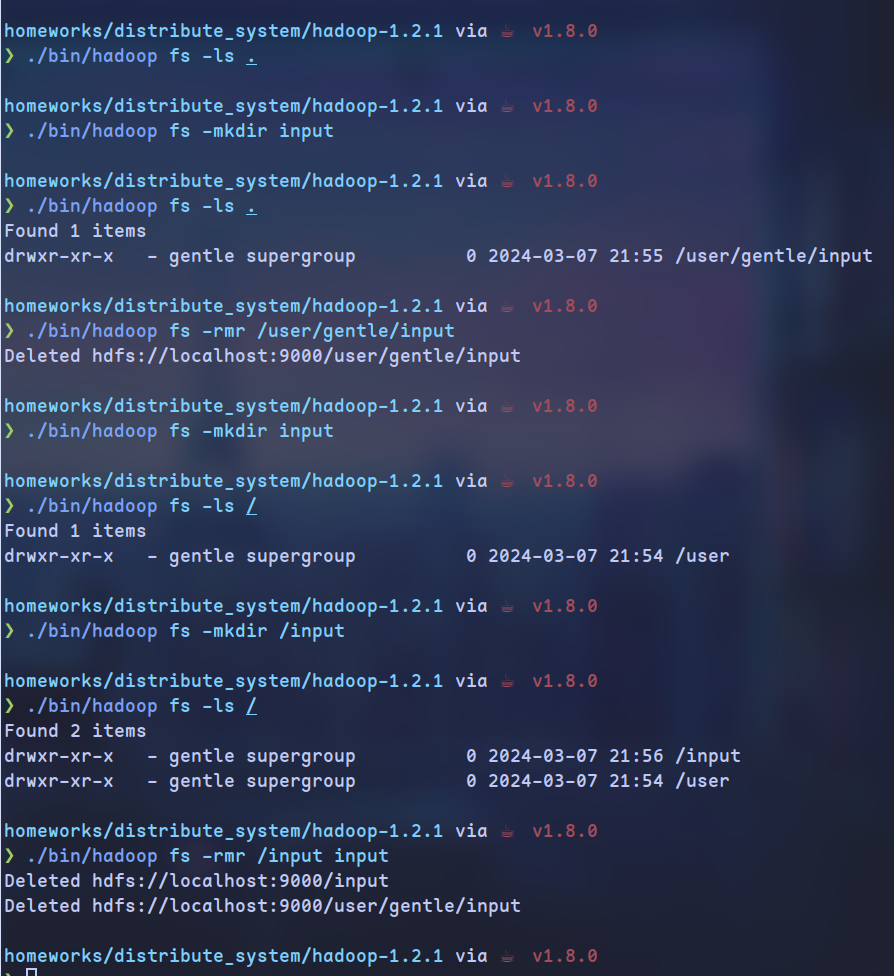
文件操作
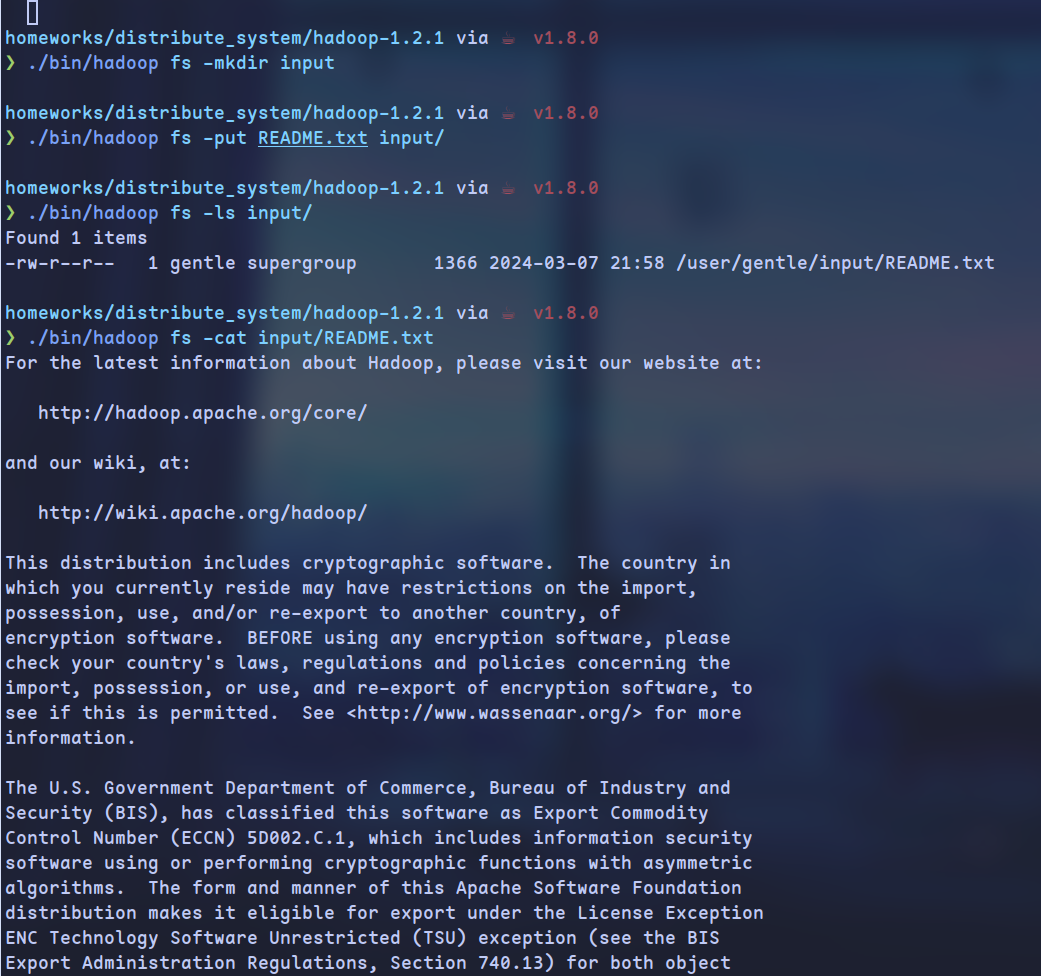
上传文件
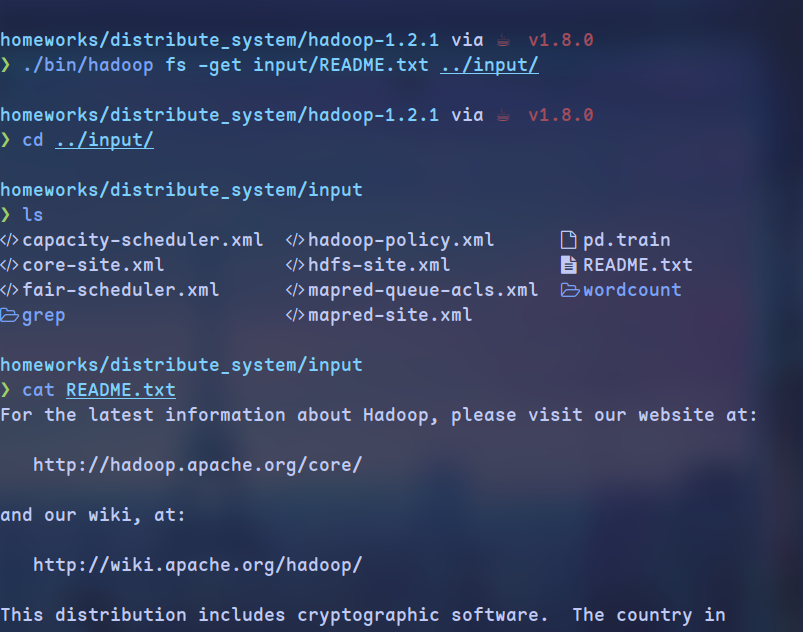
下载文件
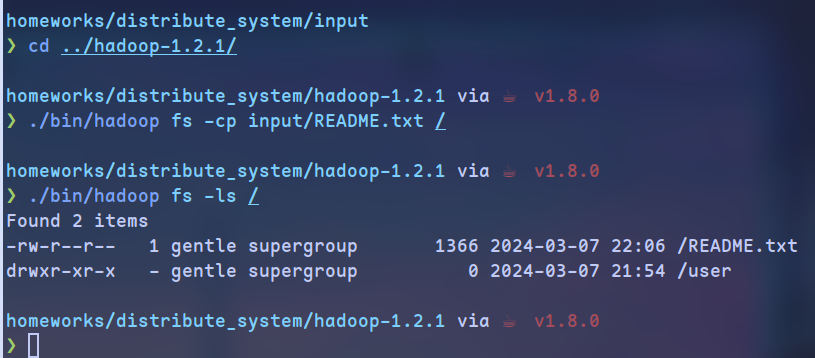
拷贝文件
启动Map reduce
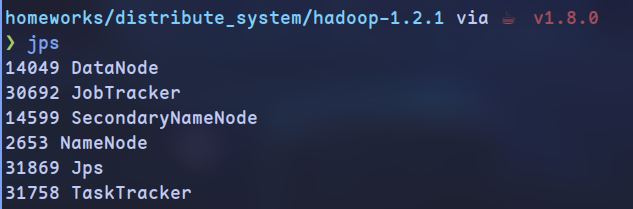
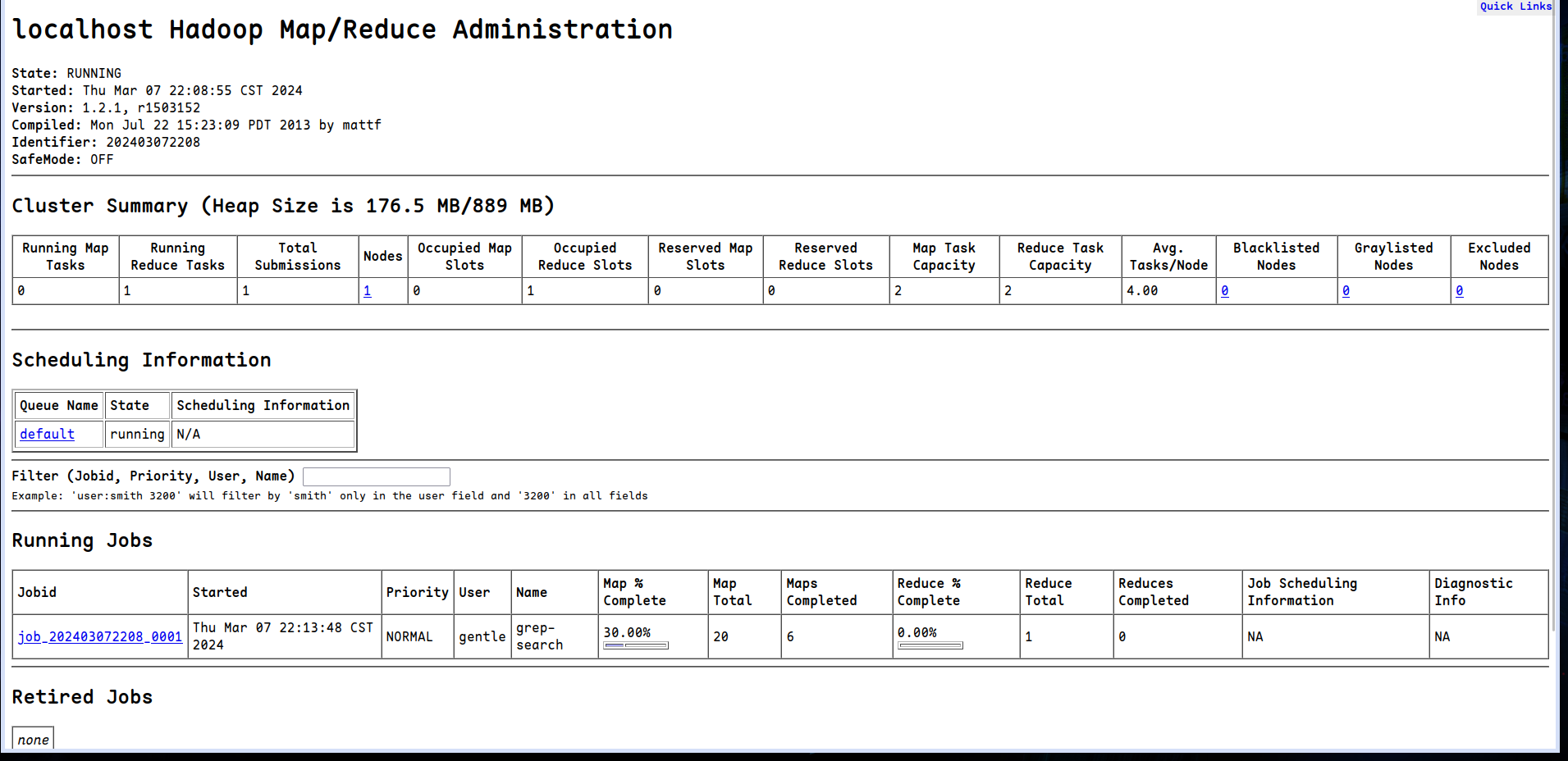

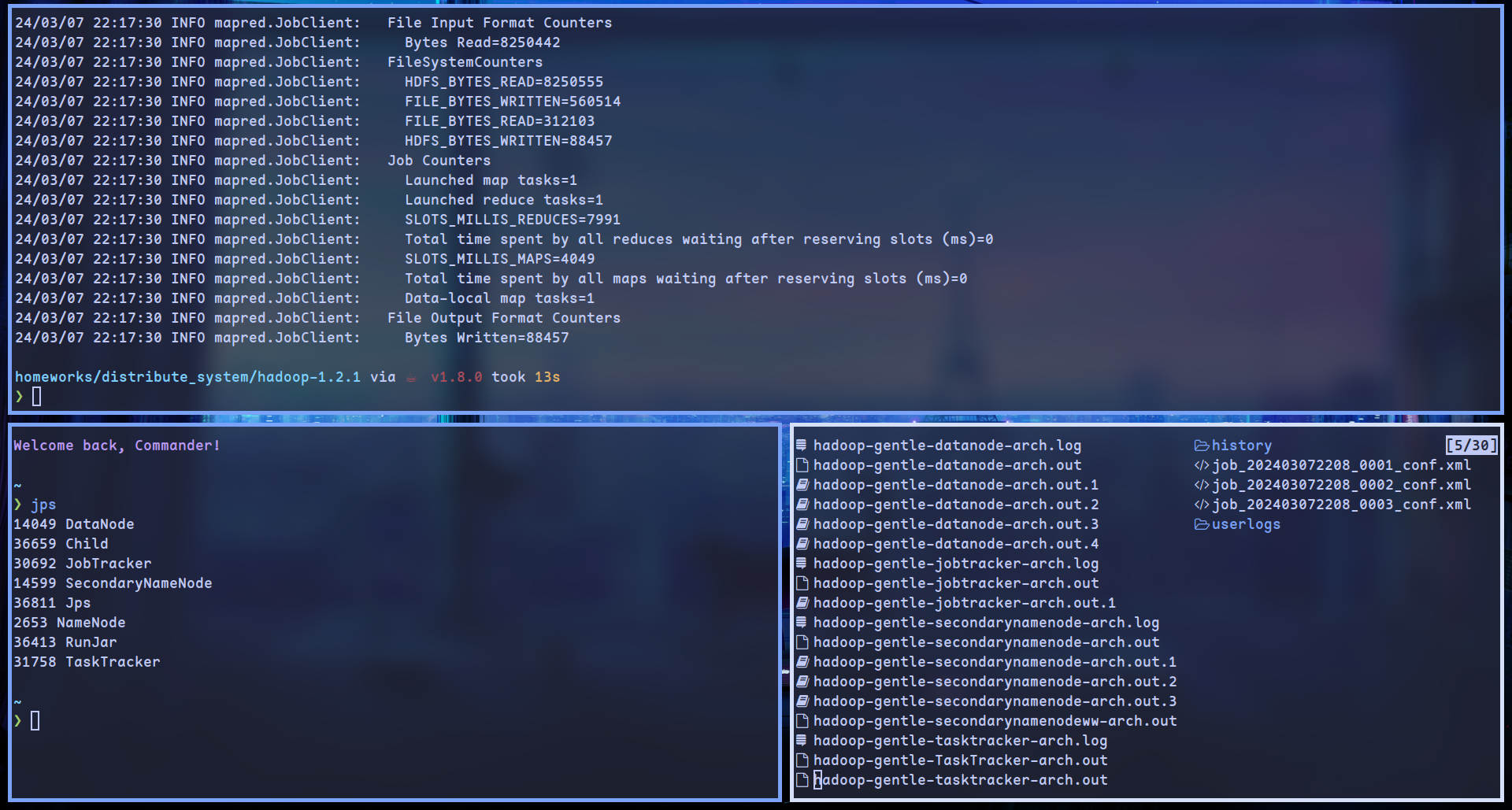
wordcount 运行结果
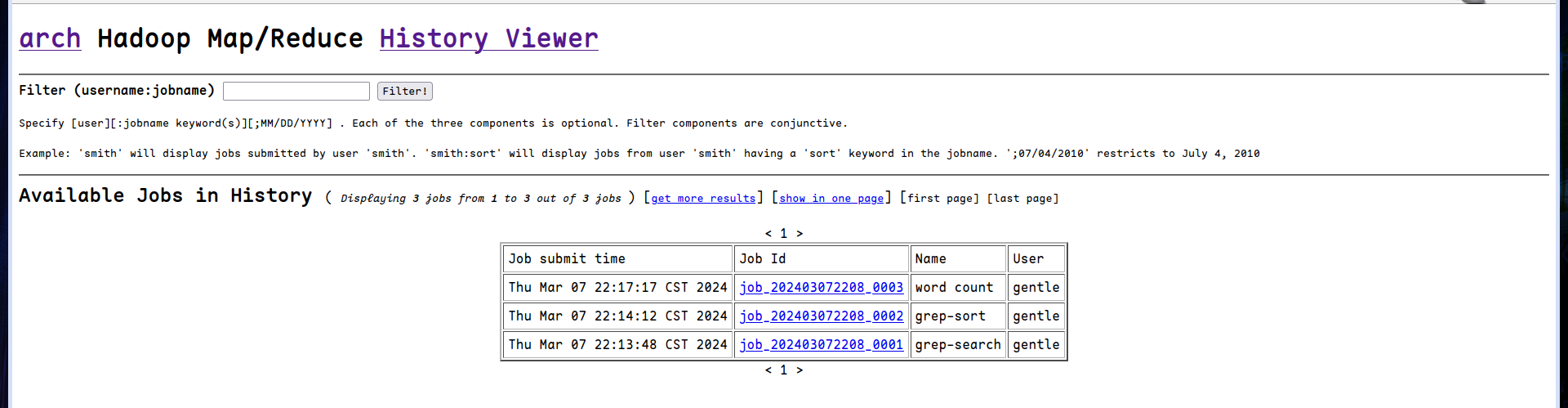
运行历史
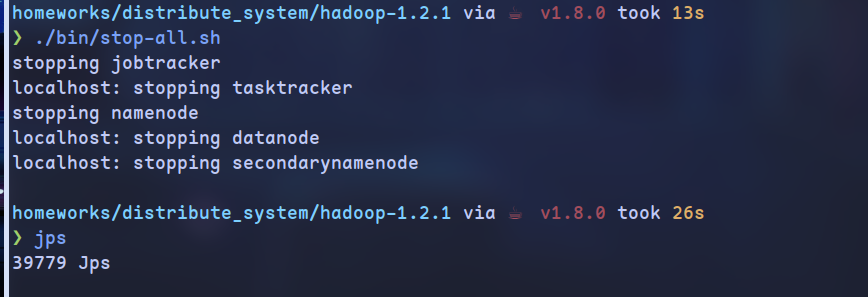
停止所有服务
思考题
- 前者设置的是每个子进程的最大内存,后者设置的是整个hadoop的最大内存
- FsShell进程执行文件操作,在此事例中,其负责将本地文件上传至Hdfs文件系统中
- HDFS: SecondaryNameNode/NameNode/DataNode; MapReduce: JobTracker/RunJar/TaskTracker/Child
- 通过fsck命令查看(
./bin/hadoop fsck /user/gentle/input -files):
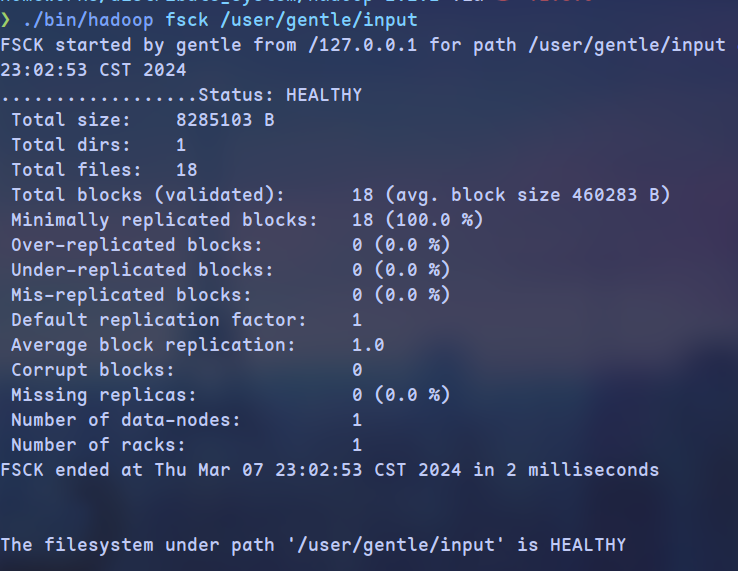
如图,input文件夹占据了18个块
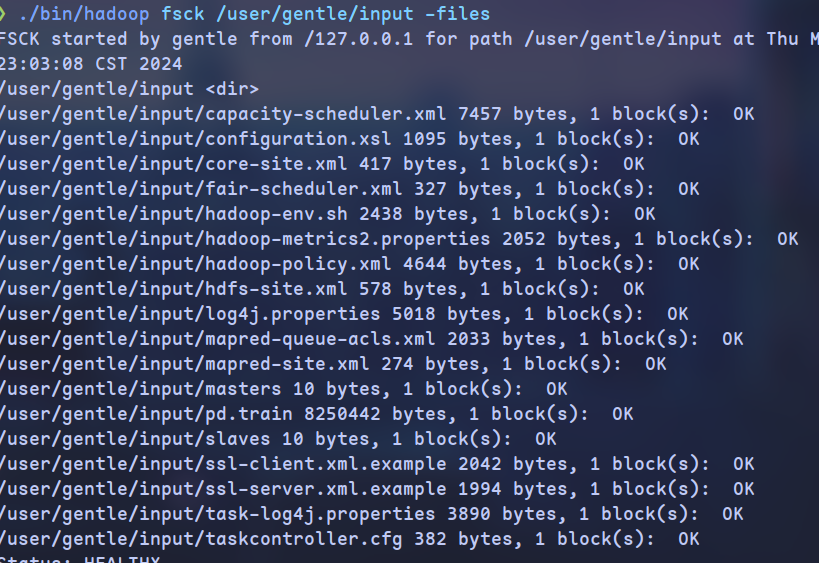
添加-files参数,可以查看每个文件的详细块占用:
- 无论是map还是reduce都没有改变,因为 Map 任务的数量通常与输入数据的分片数量相关。如果输入数据被划分为较少的分片,那么可能无法实现指定的 Map 任务数量
- 同理
Hadoop部署实验报告
https://gentlecold.top/20240307/hadoop-deploy/