MIT6824-Spring2024课程笔记
本文最后更新于 2025年9月23日 晚上
刷完CMU15445,继续开坑6824
课程笔记
公开课最新只放了2021版的,所以笔记也是基于此,但是Lab做的是2024版的。
不同于CMU15445,课程没有PPT,但是官网放了官方笔记
和学习CMU15445时一样,本笔记只记录关键词
Introduction
- why distributed
- connect(sharing)
- increase parallelism
- tolerate faults
- achieve security(isolate)
- history
- dns/email
- datacenters(web)
- cloud computing
RPC and threads
- using channels/using mutex+cond
- sync.Mutex / sync.NewCond / cond.Broadcast / cond.Wait
- remote procedure call
- client -> stub -> stub -> server
GFS
About GFS: https://zhuanlan.zhihu.com/p/354450124
- fault tolerance -> replication -> consistency
- ideal consistency
- gfs: big/fast/global
- gfs client/master/chunkserver
- master
- filename -> array of chunk handles
- chunkhandle -> version number/list of chunk servers
- log + checkpoints
- relax consistency model
- if some success, but some is error. Retry, but the success will write twice
Primary/backup replication
About VM-FT: https://www.cnblogs.com/brianleelxt/p/13245754.html
- state transfer / replicated state machine(physical/logical)
Raft
About Raft:
-
prev pattern: single point of failure
-
majority rule
-
no split brain(using term) / maybe split vote(using election timeouts)
-
logs may cliverge
项目思路
MapReduce
Master为Worker分配任务,输入数据(来自GFS),Map将中间数据存储在本地,Reducer通过remote的方式获取,最后输出到GFS
当worker在一定时间内没有反应,就认为出了故障,此时重新执行,并且这个worker上执行成功的所有map都得重新执行(认为这个worker无法被访问了)
Map和Reduce可能重复运行,但是结果是不变的
Map过程为生成一组KeyValue对,然后对Key做partition将结果分到nReduce个桶中
Reduce读取这个桶下的所有中间文件,将所有KeyValue对按照Key排序,然后得到每组Key[Values]传入用户reduce函数得到结果
文件结构
给出的main/mrsequential.go为单线程mapreduce参考文件
需要实现伪分布式mapreduce,主线程为main/mrcoordinator.go和main/mrworker.go
在本次实验中,map的结果存储为文件,不用考虑reducer对文件的remote调用
另外在mrapps目录下放置了很多mapreduce的应用文件(例如wc.go),以插件的形式加载
需要修改的是mr目录下文件
整体思路
- 一个任务包括任务类型、任务编号、输入文件名
- Coordinator初始化时即分配好Map任务
- Worker初始化后先向Coordinator获得一个worker_id,然后向Coordinator请求任务,拿到任务并执行成功后,通知Coordinator
- 若任务已完成,不再接受其他此任务的成功完成,同时将记录Map任务完成后生成的中间文件名
- Worker生成中间文件命名为
mr-X-Y-W,分别为Map任务编号,Reduce任务编号,Worker编号 - 每次分配任务都开一个后台线程,睡眠10s然后检查任务是否完成,否则将任务重新添加
- 通过Channel添加和分配任务、通过WaitGroup判断任务完成阶段(Map->Reduce->Finish)
结果
任务的容错处理比较简单,只要10s内没有结果就再安排一次任务,这样可能多个Worker同时执行同一个任务,由于Map中间文件名已经通过Worker编号标识,并且Coordinator只认首次完成成功的结果,所以不会造成冲突,而对于Reduce来说,由于每次Reduce的结果都一样,可能有多个Reduce同时写一个输出文件,但是结果不会受到影响
sh test-mr-many.sh 500 运行500次没出现故障
Key/Value Server
实现Put、Get、Append操作,底层用map存储即可
需要保证线性化,考虑因网络问题从而多次发送的情况,需要保证同一个操作的结果是一样的。主要针对写操作,需要保证不会重复写
对于客户端来说,客户端之间是可以并发请求的,但是一个客户端一次处理一个请求。对于服务端来说,需要知道请求来自哪个客户端,以及请求的序号
可以通过客户端的标识和操作的index(单调递增)作为操作的一个唯一标识(uuid),index用来判断是否为同一个请求,客户端的标识用来区分不同客户端间的并发请求
另外Append要求返回的是旧值,所以需要额外添加一个uuid->value的map用以记录旧值,为防止内存占用太多,这时就可以根据index来判断之前的操作是否完成
Raft
实验仅需修改raft.go文件,测试代码位于raft/test_test.go
Part A: leader election
阅读测试代码,首先根据论文图2完善raft相关结构,然后在Make函数中进行初始化。
另外由于测试要求1s不超过几十次心跳发送,所以设置心跳发送间隔为100ms,选举超时设置为300~600ms,同时设置ticker每10ms检查是否需要进行选举。
具体步骤为,ticker每10s检查超时,如果超时则变为candidate,重置时间,给自己投票,然后广播发起选举,为每个节点启动一个goroutine,发起RequestVote RPC调用,见函数handleRequestVote
在handleRequestVote中,处理RPC调用的reply,如果得票超过半数,则变为leader,否则如果遇到新的term,则从candidate变为follower。变为leader后启动heartbeat goroutine。
在heartbeat中,每100s为每个节点启动一个goroutine,发送不包括entries的AppendEntries RPC调用,见函数handleAppendEntries。
在handleAppendEntries中,处理RPC调用的reply,如果遇到新的term,则从leader变为follower。
函数调用关系为:
flowchart LR
ticker --> handleRequestVote --> heartbeat --> handleAppendEntries然后就是RPC函数过程,对于RequestVote来说,如果request的term更大,则更新状态(follower,term),同时重置超时时间,返回voteGranted为true,否则只返回false
对于AppendEntries来说,如果request的term更大或相等,则更新状态(follower,term),同时重置超时时间,返回success为true,否则只返回false。
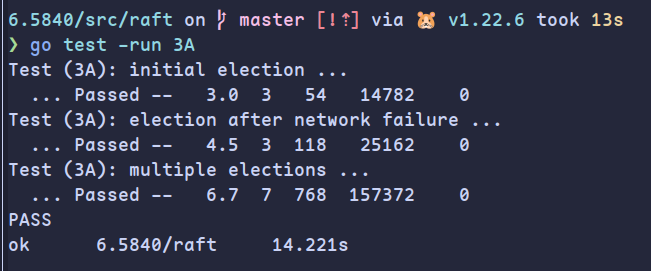
测试结果如下:
Part B: log
首先考虑raft算法本身,一个index和term唯一确定一个log,已经commit的log不会丢失,已经apply的log不会在此处被其他节点apply到不一致的log,rpc的调用是幂等性的
在代码编写过程中可以多考虑一下是否满足了这些条件,考虑一下leader/follower/candidate的宕机或者网络分区是否会破坏这些要求
本部分的重点是nextIndex和matchIndex,leader将根据这两个属性来进行节点共识处理
rpc struct
首先根据论文完善rpc相关结构
其中对于属性nextIndex[]和matchIndex[]:这两个属性由leader节点管理,前者记录每个节点下一个需要的log的index,后者记录每个节点与leader匹配的最大的log的index,在理想情况下,这两个数组实际是一样的,问题发生在重新选出leader时,前者将初始化为leader的最大的logIndex,而后者将从0开始往后递增。从作用上来看,leader根据前者找到prevLog进行一致性检验,根据后者判断majority的log复制,来更新commitIndex
basic process
客户端将从Start函数处提出请求,然后又raft来达成共识,如果当前节点是leader,此函数会在本地增加log,并立即返回。之后将进行共识,不保证一定达成共识。
修改heartbeat函数,原先发送的AppendEntries的entries默认为空,但此时会根据对应节点的nextIndex的值发送从此处开始之后所有的log,同时根据此值确定prevLogIndex和prevLogTerm,以进行一致性检查。如果nextIndex和leader的log长度一致,则不需要发送log,保持发送心跳,但仍要进行一致性检查。
修改AppendEntries函数,添加一致性检查的过程,分为三种情况:
- prevLogIndex处没有log,返回false
- log为空或者一致性检查成功,进行append操作,返回true
- 一致性检查失败,返回false
需要在进行append时确保覆盖操作,即覆盖PrevLogIndex之后所有的log为leader的log,但同时要注意忽略已经复制的log
有一种极端情况,leader发送了两个AppendEntries RPC,前者需要复制log1,后者需要复制log1和log2,由于种种原因,第二个rpc先得到处理和返回,而第一个rpc后到,我们需要保证如果log2被commit了,后到的rpc不会导致log2丢失。通过检查传输的entries是否和follower的log有不一致(只需检查最后一个entries),如果有,则进行正常的截断合并,否则不进行截断,这样可以同时确保不一致的log被丢失,一致的log不被覆盖。此时还要考虑nextIndex的更改,如果复制成功,nextIndex一定不会减少。当然也可以不管nextIndex,只要确保commit的log不会丢失就行
对于leader,根据reply的success判断日志复制是否成功,如果成功,更新nextIndex和matchIndex,如果失败,更新nextIndex为不一致的位置
另外修改投票逻辑,选出的新leader需要重置nextIndex和matchIndex
commit and apply
对于leader,在每一次日志复制成功后将检查matchIndex,即找到最大的index,使得log[index].Term为当前term(对应论文5.4.2要求commit当前任期下的log才能commit之前的log),并且matchIndex数组中的大多数大于等于index(注意这里不用考虑leader本身的matchIndex),则可更新commitIndex为index
对于follower,在AppendEntries中,当且仅当成功进行日志复制,即完成同步,才更新commitIndex为min(len(log), LeaderCommit)
对于所有节点,apply的过程放在ticker函数中,即每10ms检查一次LastApplied和CommitIndex,将尚未应用但已提交的log通过applyCh通道传递来表示应用到状态机
election restriction
为避免论文5.4.1所说的问题,添加选举限制,即选举时多传一份LastLogIndex和LastLogTerm,当且仅当candidate的log比follower的新才能获得选票(term大的或者term相同时,index大的),来确保不让log不一致的节点当选leader覆盖掉已经commit的log
fast rollback
在原先leader处理日志复制失败的情况时,是一个log一个log回退的,如果出现大量不一致log会导致效率下降(尽管这种情况实际很少发生),为提高效率可以根据不一致log的term来回退
为此需要在AppendEntries的返回中增添两个属性ConflictIndex和ConflictTerm,考虑复制失败中的两种情况:
- prevLogIndex处没有log,更新ConflictIndex为本地最后一个log位置
- 一致性检查失败,更新ConflictIndex为冲突log的任期下的第一个log位置
leader处理失败时,可以直接更新nextIndex为ConflictIndex,也可以确认此处log的term是否为ConflictTerm,如果是则表示这里已经一致了,就nextIndex++,直到找到不一致的地方,这样可以避免多传输不必要的log
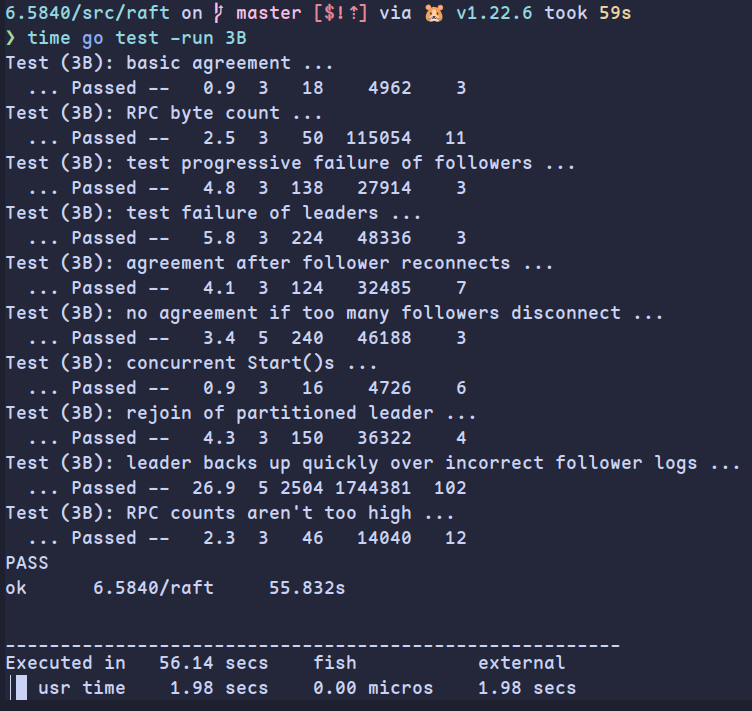
测试结果如下:
Part C: persistence
B部分只考虑了网络分区的影响,此部分进一步考虑节点的宕机问题,需要存储状态,包括currentTerm和log[],前者用来确保一个任期只有一个leader,后者用来为复制状态机提供数据回滚,即重新应用。而剩余的任何属性均不需要持久化。
代码使用Persister模拟磁盘交互,一般为需要持久化的数据,在每次更改时写入磁盘,在重启时读取数据即可
另外考虑到此部分的测试代码将更加严格,就算之前的测试能够通过,此处也不能保证百次测试都通过,本人遇到的问题有:
- 注意重复/过期/乱序RPC的情况,主要是确保已经commit的log不被截断丢失,并且log的term必须是单调递增的。同时注意忽略过期处理的term,以防过期的term让不该当选的节点当选
- 注意重置选举超时的时机,变为follower后要记得重置
- 调整心跳间隔为50ms,选举超时为150ms-300ms
- 在leader当选后先共识一份空log,来让之前未提交的log能够提交
Part D: log compaction
考虑到每次重启都要重新应用log,为提高效率,为状态机状态建立快照,从而压缩log
首先完善SnapShot函数,其由server定期调用,建立快照并交由raft进行持久化处理,raft在收到后需要根据快照包含的最后一个log的信息来移除已经被快照包含的log。注意我们需要保证能够进行快照的log都是已经提交的,所以要根据index和commitIndex来判断是否应该进行快照处理。
潜在的死锁问题:在应用log时,如果一次性应用多个log,即向applyCh传递多个msg,由于3D中的测试会在取出一个后调用SnapShot函数,而SnapShot需要获取锁,然而此时
applyCh<-msg仍处于阻塞状态,从而无法释放锁。解决办法是在传递之前先释放锁,同时注意lastApplied的修改逻辑,避免重复应用。
由于之前使用切片来存储,建立快照后需要考虑下标问题,为此我们需要更改之前所有涉及到log下标的地方
实际是在逻辑上将log分为两部分,一部分是快照,一部分是log,log的下标是不变的,但是物理上访问log切片需要根据snapshot.lastIncludedIndex更改下标
另外还需要注意lastLogIndex等参数的改变,需要根据snapshot分情况讨论
另外为AppendEntries增加逻辑,如果因为PrevLogIndex包含在snapshot中所以找不到或者snapshot的一致性检验失败,说明follower的所有log都不匹配,设置conflictIndex为0后返回false
而在心跳中,如果发现nextIndex小于snapshot的lastIncludedIndex,则说明需要发送快照,即InstallSnapshot RPC
对于InstallSnapshot RPC,同样要注意RPC的幂等性,通过检查follower在lastIncludedIndex处的term是否和snapshot的Term匹配来决定log的保留。接收返回后,更新nextIndex和matchIndex
最终结果
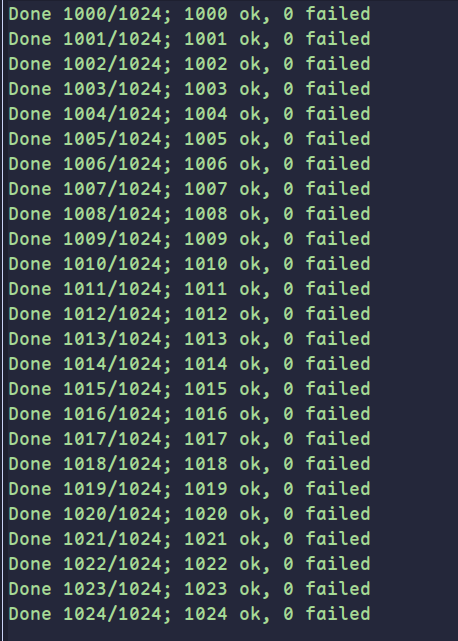
1024次批量测试均通过:
潜在bug:
- appendEntries时传递的log如果只是通过切片获取的话,实际只是获得了引用,或造成潜在的冲突,需要使用copy
Fault-tolerant Key/Value Service
此实验将完成raft算法和客户端的交互,实现一个线性化的分布式键值服务
另外和lab2一样,此处认为一个client一次发送一个请求,不同client间并发发送请求
Part A: Key/value service without snapshots
首先考虑基本的流程,客户端先随机找一个server发送rpc,服务端收到后,如果是leader则进行共识流程,否则返回其所知道的leader,下一次客户端选择这个server,如果超时则随机再找一个server
另外server将启动一个后台的应用进程,在受到applyMsg后进行应用
我们需要解决两个主要问题:
- 如何确定操作完成了共识?一开始是判断LastApply是否超过这个log的index,超过了说明操作已经完成,但这样是有问题的,因为这个index上的log可能会变成别的操作。实际使用clientId+seqNum作为Uuid,可以通过管道,为每个index分配一个管道,如果完成apply则发送log的Uuid进行唤醒和判断。也可以通过记录uuid是否被共识来过滤一部分重复,同时还要注意设置超时,以防无法共识造成阻塞。
- 如何过滤重复操作?首先不能在rpc处过滤,因为重复append是不可避免的。可能已经完成了共识但是client没有收到,然后在另一个server又发了一遍,也可能没有完成共识,需要再次append log。所以只能在apply端通过uuid过滤重复
实验没有考虑只读优化,直接将get操作作为一个log进行共识
最后注意server关闭时applyCh阻塞造成goroutine泄漏的问题(没有消费端,可以设置一个超时关闭)
Part B: Key/value service with snapshots
这部分添加需要服务端手动在合适时机建立快照。
实际只需要在状态机中收到applyMsg并应用后,判断raftstate是否超过maxsize,若超过则建立快照,需要保存当前的kv对信息以及过滤重复的表信息,然后调用Snapshot将快照传给raft层即可。
但是如果leader一次性获取了大量的命令导致raftstate过大,这时没收到一个applyMsg就会建立一次快照,为了避免性能影响,可以要求必须在上一次建立快照时的index之后n个index后才能再次建立快照。
这时server端就完成了,接下来是历史遗留问题,由于lab3中对snapshot的测试过于宽松导致许多问题在此暴露:
- leader可能install新的snapshot给follower,所以follower的server在调用Snapshot传送快照时,不能让旧的snapshot覆盖掉新的
- 同样在InstallSnapshot中,follower的snapshot可能比leader的新,这时旧的snapshot也不能覆盖新的,log也不能影响
- 在AppendEntries中,如果遇到prevLog处于节点的snapshot内(同时发送了AppendEntries和InstallSnapshot RPC,后者先到达就会遇到这种情况),则不要更改log或是快照,返回false并且让nextIndex更新到len(log)+snapshot.Index,再重新进行一致性检查
其实只要记住snapshot所包含的必须是已经apply的log,代表snapshot一定是一致的,所以旧的不能覆盖新的(导致log丢失),对snapshot不需要进行一致性检查,但是我之前误认为snapshot可能会不一致了
最终结果
1024次测试成功