Raft论文浅读
本文最后更新于 2026年3月19日 下午
论文为:In Search of an Understandable Consensus Algorithm (Extended Version)
https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
本文仅记录个人学习的见解,与原文搭配更佳,如有错误,欢迎指正
1 Raft 介绍
作为共识算法,Raft有三个特性:
- 只有一个Leader
- 使用随机定时器来选举
- 允许运行时改变配置
2 复制状态机
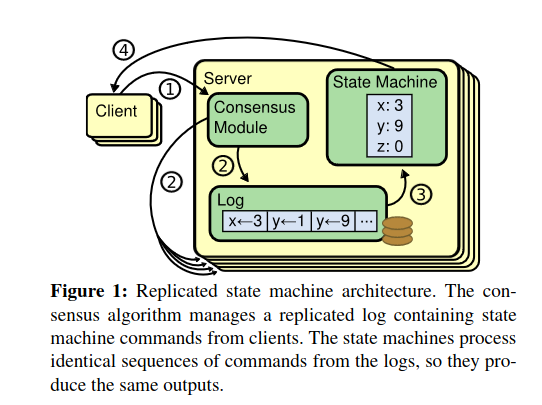
共识算法处理Client的命令,负责Log的同步,Log应用到状态机上,然后通知Client
3 Paxos的问题
- 难以理解
- 实践较少
4 可理解性设计
- 将问题分割
- leader election
- log replication
- safety
- membership changes
- 减少状态空间
5 Raft算法
首先选举一个Leader,只有Leader在线时才能处理
Leader需要处理来自客户端的Log Entries,复制这些Log,通知服务器在合适的时候应用这些Log
此节将介绍Raft的三个方面:
- 当一个Leader寄了要进行新的选举
- Leader需要将Log复制给所有节点
- 当一个状态机应用Log时,保证所有的状态机在这个index下都应用这个Log
5.1 Raft basics
- 节点都有三个状态:Leader、Follower、Candidate
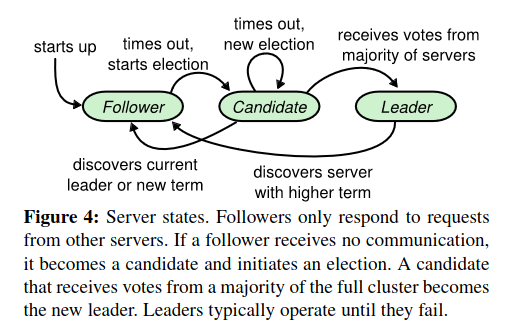
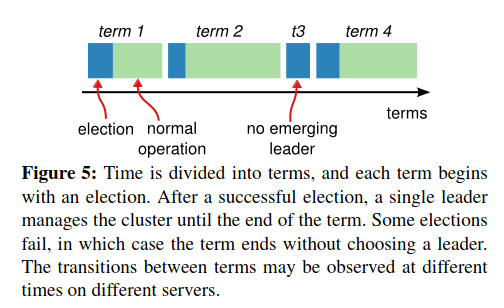
- Terms充当逻辑时间,一次Term由选举产生,选举可能出现Split vote导致没有Leader选出,此时重新产生选举
- 当Server间通信时,会更改Term和状态,对于两个通信的Server:
- 旧的Term会同步到新的Term
- 如果Candidate或Leader是旧的Term,则转为Follower
- 拒绝旧Term的请求
- Terms保证了不会产生脑裂
- Server间通过RPC通信,目前只考虑两种RPC: RequestVote(candidate)和AppendEntries(leader),也就是说Follower不会主动发起通信
- PRC并行发起,会被重试
5.2 Leader election
刚开始所有节点为Follower。Follower在一段时间(election timeout)内未收到RPC通信(将空的AppendEntries RPC当作来自Leader的心跳)则变为Candidate开始选举,一个节点只能投一票(一个任期中)
开始选举后:
- 增加Terms
- 给自己投一票
- 给所有节点发送RequestVote RPC
什么时候结束选举:
- 赢得选举
- 已经选出Leader
- 超时而仍然没有Leader
当获得Majority票数后成为Leader,开始发送心跳
可能出现Split votes,即多个Candidate但是没有Majority票数,此时等待超时然后重新发起选举。同时,使用随机化的timeouts来减少split vote出现的可能
结果表明这种方式也能快速完成选举,同时减少了逻辑复杂度(本来打算引入ranking system)
5.3 Log replication
选举出Leader后,Leader处理来自客户端的Log,向所有节点发送AppendEntries RPC。如果follower没有给出合适的应答,会无期限重试。如果收到了RPC,需要进行一致性检查(前一个Log是否有相同的index和term)
当Log被大多数server复制后,这个Log被认为是committed,可以应用到状态机上。Raft保证committed的log最终一定会被执行
不一致发生在Leader寄了的时候,Leader中的Log可能没有被committed。Raft通过覆盖Follower的Log为Leader的Log来处理不一致。Leader为每个Follower维护一个nextIndex(初始化为自己的nextIndex),当RPC被拒绝后会减少nextIndex直到一致性检查成功,然后插入新的Log
5.4 Safety
此节对Raft如何保证一致性进行进一步的解释
5.4.1 Election restriction
Raft算法通过给选举添加限制来保证被选举的Leader包含之前所有committed的Log。即发起选举时,如果follower的Log比candidate新,则拒绝投票。
如此一来,若Candidate缺失了committed的Log,则不会获得majority的票数。但是如果Candidate通过选举,仍可能包含未被committed的Log
5.4.2 Committing entries from previous terms
所以Leader选举后要完成之前未完成的工作。如前所述,Leader仍然只是覆盖所有不一致的地方,意味着可能覆盖掉旧的但是仍被majority记录的Log。为解决这个问题,Leader只有当前任期下的Log被Majority记录后才考虑commit
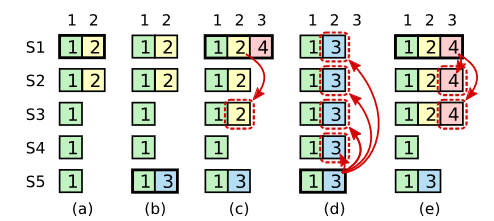
如图所示,(c)中的2并未被commit,只有(e)才能被commit,此时S5无法被选举成功。当然也有别的办法判断2是否应该被commit,或者直接更新这个Log的Term,但Raft中Leader不会更改旧的Log,只是Append。Raft为保持简单使用了保守的策略,虽然这样可能会导致发出2命令的客户端等待更长的时间
5.4.3 Safety argument
回顾一下raft保证的五个性质:

- 一次最多只能选举出一个Leader
- Leader只Append自己的log
- 如果两个Log的index和term相同,则此前的所有Log都相同
- 如果一个Log在Term中被committed,那之后Term的Leader一定包含此Log
- 如果Server应用了Log,那么不会有别的Server在此index处应用其他Log
此节用反证法证明第四点。考虑一种情况(即上上张图情况e),旧Leader commit了一个Log,此时有个不包含此Log的节点发起了选举,由于它需要获得多数投票,而commit的Log也被多数节点存储了,因此candidate若想胜任一定需要一个存储此Log的节点的赞同,但根据之前的限制,此时的投票被拒绝,因此不会变为Leader
证明了第四点也即证明了第五点,只要server是按照index的顺序应用Log
另外对于网络分区导致的两个leader问题,因为选取出了新的leader,majority节点的任期会更新,所以在网络恢复时旧leader会变为follower
5.5 Follower and candidate crashes
- RPC是幂等的
- 若失败则无期限重试
5.6 Timing and availability
为保证可行性,Election timeout 至少要大于等于RPC时间,小于等于机器故障间隔
6 Cluster membership changes
此节介绍如何在运行时更改配置(改变节点数量,替换fail的节点等)。通过发送包含配置的Log来应用配置。节点会使用最新的配置,尽管这个配置可能没有commit
要更改配置,首先发送结合新旧配置的Log,来达到joint consensus的效果,旧配置可能包含一部分Server,新配置可能包含另一部分Server,而Joint consensus情况下:
- Log会复制给所有的Server
- 无论是新旧配置中的Server都可以成为Leader
- majority的条件变为旧配置的Server中达到majority并且在新配置中也达到majority
具体做法如图:

先发送直到其被commit,然后发送直到被commit,至此完成配置转换,同时:
- 新加入的Server因为未包含Log导致需要一段时间才能catch up。可以先把它作为被复制的对象加入但是不考虑其为Majority
- Leader可能在新配置中被删除,此时在新配置被commit后删除Leader。所以存在一段时间Leader不考虑自身为majority,但是仍然处理Log
- 新配置中被删除的节点因为不会再收到心跳所以会发起选举,可能会导致当前leader变成follower。为解决这个问题,如果在一段时间内接受过心跳,就认为Leader存在,此时拒绝投票
7 Log compaction
raft通过snapshot的方式进行Log压缩。sanpshot将包含所有状态的值以及last included index/term
leader可能已经通过snapshot删除了部分Log,为了让slow follower保持一致,引入InstallSnapshot RPC,直接复制snapshot
考虑谁以及何时触发压缩。follower和leader都可以触发,也可以只有leader触发,但是会导致大量复制snapshot的时间。时间上一般是Log达到一个固定的大小后触发压缩。
另一个问题是写入快照的性能的问题,可以利用cow,在内存中写入
8 Client interaction
客户端首先随机选择节点发送命令,若不是leader则拒绝,并返回这个节点所知道的leader。
为避免重复执行命令,客户端为每个命令赋予独特标识,由状态机记录
对于客户端来说,Raft将保证线性一致性:
- 为避免读到旧数据(试想有两个leader,其中一个是挂了重启的),让leader起码一次获得majority返回后再返回读数据
- 为避免脏读(上任的Leader可能包含未commit log),让leader上任后首先commit这一任期下no-op的log
总结
后续为实验以及性能上的评估。设计了实验验证raft可理解性比paxos更好,并且性能与其差不多。但是强leader性质仍然会限制一些性能,Raft仍有可改进的地方(用batching提高并行)
最后可以看看可视化raft来加深理解:https://raft.github.io/
具体的实现可见MIT6824的笔记