向量数据库调研
本文最后更新于 2026年3月19日 下午
摘要
随着大语言模型的兴起,向量数据库得到越来越广泛的应用,其面临的主要挑战是大规模向量数据量下的查询问题。于此同时,随着多模态技术的发展,非结构化数据查询越来越重要,这时需要转换成向量查询、混合查询问题,而向量数据库则专门针对此方面进行优化,期望处理大规模数据集。本文将介绍向量数据库的应用场景、面临挑战,而后简要介绍其与传统数据库的区别,最后详细讨论向量索引的发展,以及其所用的主要技术。
简介
本文的Survey对象是向量数据库,相比于传统数据库的基于内容本身的查询,向量数据库提供了根据数据的语义信息来对数据(尤其是非结构化数据,例如图片)进行更为深入的查询功能。其中向量来自于各种Transformer结构,将数据转化为一组定长的向量编码得到,这些编码将包含模型学习到的数据的特征信息。而向量查询则是通过算法寻找与查询向量相似的向量数据,这样可以实现复杂数据的搜索,并非简单的内容匹配,还包括特征匹配。
向量数据库则专门针对这一功能进行优化,建立向量索引用以加速相似性查询。当然除了专门建立一种数据库,在现有的基础上提供向量搜索扩展是一种更加方便的做法(例如pgvector)。然而随着大语言模型的兴起,向量查询将得到更多的应用,在模型的训练中,也需要一个专门的数据库来存储和管理训练产生的向量参数。
以GPT为例,向量数据库将帮助其实现‘记忆’的功能,当向GPT提供一份文档时,会将文本转化为向量,然后当用户提出相关问题时,也会将搜索内容转换为向量,然后在数据库中搜索相似向量,匹配相似上下文,再返回给GPT,这样可以大大减少GPT的计算量。除了文本,随着多模态模型的发展,语音、图片、视频等等数据都可以加以利用。
目前的挑战是,常见的各种搜索应用(大语言模型、推荐系统等)可能涉及数十亿向量的搜索量,并且期望毫秒级的查询延迟。与此同时,向量搜索核心为相似性搜索,依赖相似度的概念,然而这个概念需要针对不同应用提供不同的查询规范,并且相似度的计算比普通比较花销更大,其次,单个向量可能很大,检索的成本更高并且会占用大量内存,最后,混合查询(同时比较属性和向量)目前并没有高效的做法。
本文Survey内容主要为向量索引方面常用的各种技术,由于向量集合缺乏可序的性质,传统的索引技术(B+树)难以直接应用,所以需要单独的向量索引技术,特别是能处理大规模数据量的索引技术,目的为减小搜索量,来加速向量查询过程。
基础知识
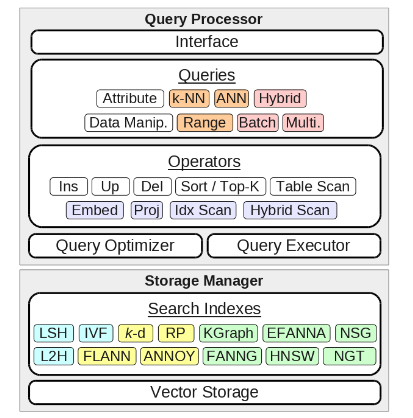
相比于传统数据库,向量数据库的设计主要在查询处理和存储管理方面有所不同。对于查询处理,首先是数据操纵上,分为直接和间接操纵,前者由用户直接输入特征向量,后者用户只需输入具体的数据实体,而由数据库负责处理编码模型。其次是相似性测量,包括欧几里得距离、余弦相似度、点积相似度、汉名距离等等,然后是基本的搜索查询,常用的方法有k近邻算法(KNN)、近似近邻算法(ANN),常用的搜索有k近邻搜索(提供查询数k)、范围搜索(提供相似度阈值),除此之外还有混合查询、批次查询、多向量查询等。最后是基本的操作算子,主要是相似度投影算子,将向量投影至对应相似度的集合中。
而在存储方面,最主要的区别是向量索引。由于缺少可序型,向量索引依赖分区技术,包括随机化分区(randomization)/学习分区(learned partitioning)/可导航分区(navigable partitioning),在结构上又分为table/tree/graph三种类型。
早期的向量索引始于哈希技术,通过哈希进行桶映射来实现减少搜索量,而随着大语言模型、推荐系统等应用的兴起,向量数据量越来越大,向量索引发展出更多的形式,如基于树结构的FLANN(2009)、基于图结构的HNSW(2016)等,同时也引入机器学习、深度学习等方面的技术来进一步提升性能。
Survey内容
进行相似性搜索时,如果要在海量数据中找到最相似的几个向量,需要对数据库中的每个向量进行一次比较,这样的计算量是非常巨大的,通常有两种方式提高效率,一种为减少向量大小(进行降维、压缩),一种为减小搜索范围(利用向量索引,聚类或组织成树状、图状),此节主要从减小搜索范围方面介绍向量索引所用的技术。
Table based indexes
此类索引将向量集合映射到不同的桶中,相当于哈希/聚类,所以关键在于哈希技术,如果桶太大可以提升召回率,但是会导致搜索效率变低,所以需要取一个折衷。目前使用的技术有局部敏感哈希(LSH)、哈希学习(L2H),目的在于在高召回率的情况下提升性能,进一步还有量化压缩技术(quantization),来减少索引存储成本,提高处理大规模数据的能力。
局部敏感哈希依赖于随机哈希函数进行随机化分区,通过将每个向量哈希到L个哈希表中(需要K个从特定哈希族挑选的哈希函数进行拼接),对于查询向量也是如此,并将哈希碰撞的向量保留为候选结果。关键在于哈希族的选择,一般这类哈希函数被设计为相似度高的数据以较高的概率映射为同一个哈希值,这样可以保证较高的召回率。哈希族的选择包括E2LSH、IndexLSH、FALCONN等。
哈希学习通过机器学习得到那些可以把相似向量放在一起的哈希函数。SPANN(一种基于深度学习的向量索引,对近似近邻搜索做了改进)使用了这种技术,主要使用k均值聚类的方法得到哈希函数。结果表明此类方法可以进行很好的分区,然而其缺点为数据依赖,只针对同一种数据集有较好的表现,所以针对不同的数据还要进行针对性调参。
另外这种方法对内存占用较大,考虑使用量化压缩(有损),一种方法是将向量进行位压缩(64位浮点数压缩为32位),进一步,可以将聚类中心里的每一个向量都用聚类中心的向量来表示。然而要想获得较好的聚类结果,需要的聚类中心数量会随维度成指数型增长,一种方法是积分量化(product quantization),通过将原空间划分为多个子空间,在子空间上分别做聚类,避免过高的指数累计。
Tree based indexes
此类索引通过递归的方式分区向量集合,从而构建一颗搜索树,通常可以提供对数级的查询效率。常用的索引结构是kd树,采用确定性的分割策略(例如取中位数作为维度分割点)。另外一种方式为使用随机化手段来分割,如主成分树通过找出数据集的主成分然后沿着主轴进行分割,PKD-tree通过循环主轴进行分割,而FLANN使用随机主成分维度进行分割。当然,找到主成分的过程也会有开销,所以有一种随机投影树,采用完全随机但带有阈值的分割方式。为了提高召回率,可以使用多种树结构组成的森林结构,这种方式和局部敏感哈希类似。
Graph based indexes
此类索引将图叠加在向量之上,将向量作为一个节点,各个节点之间构成图,从而得到节点间的距离,这样就可以将向量连接起来,使用相似度作为权重,进行相似度查询时,就可以通过边搜寻。以k近邻图(KNNG)为例,每个向量与k个最相似的向量连接,这样可以在常数时间内完成k近邻搜索。另外还有单调搜索网络(MSN)和小世界图(SWG),目的是为了选择更易导航的边。
这类索引的时间开销主要在索引构建部分,在构建过程中也会使用各种分区技术。对于KNNG,显然构建图需要的时间。一些优化旨在通过迭代的方式构建接近于KNNG的图,例如KGraph最开始为一个随机的KNNG,通过检查图中每个节点的二阶邻居来逐步优化。进一步为了提高召回率,EFANNA则是使用由随机k-d树森林构建的KNNG开始逐步优化。
对于MSN,其保证了任意两个节点之间存在单调搜索路径,所以可以利用贪心的办法搜索(每次搜索最小路径),但类似于KNNG,此类结构仍然难以构建。目前的方法是一边添加边,一边检查图的质量,即在给定的两个节点间进行最优优先搜索,持续添加边直到可以找到单调搜索路径(搜索实验)。同样也会使用随机图或者近似KNNG来作为初始图,有些索引(FANNG)会进行大量的搜索实验,另外一些(NSG、Vamana)使用一个导航节点作为所有实验的源节点。
最后是SWG,结合了两种特性,其一是路径随节点数量成对数增长,其二是使用最优优先搜索访问的节点数量也是对数增长,对数复杂度可以减少访问,提高效率。一种可导航的小世界图(NSW)为每次将向量加到数据库中的时候,先找到与它最相邻的向量,然后将它们连接起来。HNSW进一步使用了分层的结构,为每个节点分配一个最大层级,最底层包含所有的节点,越往上节点越少,成指数衰减,这样可以避免平面图度数过高的问题。其本质类似于跳表,最上一层提供快速搜索,越往下提供越精确搜索,实际是空间换时间。

目前有一些开源库提供了向量搜索的功能,例如FAISS,Annoy等,这些库都或多或少采用了上文提到的技术。
总结
本文综述了向量数据库技术的现状,简单介绍了向量数据库的应用意义以及向量查询处理、相似度等方面,详细讨论了向量索引方面的技术进展。向量数据库的一大目的是提供大规模向量查询功能,其核心是相似性搜索,可以利用向量索引组织向量集合,加速查询处理,但是需要在召回率与性能之间取折衷,还要考虑构建索引的复杂度。从哈希/聚合到树结构、图结构,向量索引发展出各种形式。随着相关技术的不断发展,有望在更多的应用场景中发挥重要作用。