VBase论文浅读
本文最后更新于 2026年3月19日 下午
论文为:VBASE: Unifying Online Vector Similarity Search and Relational Queries via Relaxed Monotonicity
1 介绍
查询逐渐复杂,促使了向量搜索与关系数据库的结合。另外由于高维度向量难以保持单调性,现代向量索引仅支持TopK近邻查询。
在混合查询中,一种做法是选择k个记录,然后建立临时索引,再在索引之上进行属性过滤,问题在于,如果要求的查询是最相似的n条记录,则需要设置一个保守的较大的k,会导致次优的查询性能。
于是提出VBase,利用放松单调性(Relaxed Monotonicity)的概念,索引遍历首先大致定位到目标向量的最近区域,然后逐步远离目标区域进行近似移动。这将可以使用Next接口进行遍历,而非TopK,并提供更好的性能。
2 背景
提出四种向量查询场景:
- 单向量TopK
- 单向量TopK + 属性过滤
- 多列向量TopK交集
- 向量相似性过滤
目前没有系统能高效支持所有的查询
另一方面,向量和传统数据库索引之间的语义差异使得提供一个统一的系统来高效运行各种复杂的在线向量查询变得困难。传统的向量索引针对TopK进行优化,仅提供TopK接口,可以选择k个然后根据距离排序建立临时索引,问题在于选择合适的k是困难的(如前文所述)。
3 VBase设计
3.1 放松单调性
在传统向量索引中的遍历并不符合单调性,无法直接利用。但是可以发现一种两阶段遍历模式,第一阶段大致在接近目标区域,存在较大波动,第二阶段逐渐稳定,并逐渐远离目标。
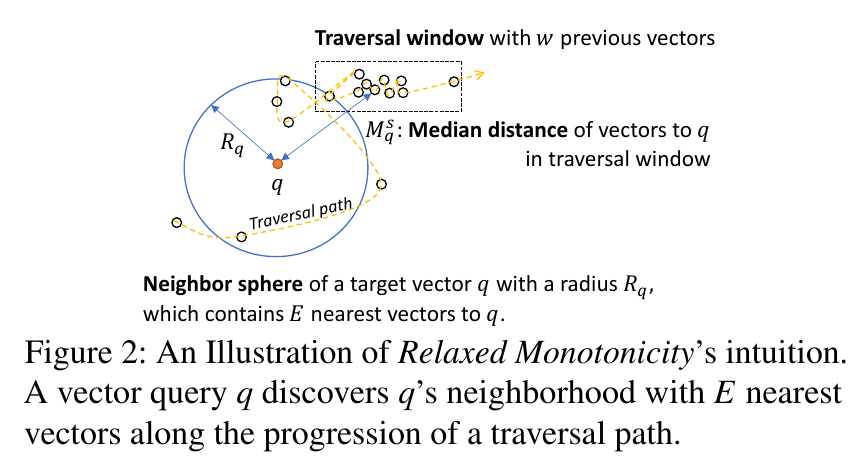
现讨论两个参数和:
- 为s次向量遍历中,能包含q的E(E>=K)个近邻,会随着遍历而减小并趋于稳定
- 为s次向量遍历中,取最近w个遍历的向量的距离的中位数
定义放松单调性为,存在一次遍历s,在s之后的任意遍历都能满足
满足这一性质后即可认为进入第二阶段,此时若已经找到足够多的结果就可以终止遍历
对于不同的索引有不同的E和w设置,各个索引有责任调整超参数来保证放松单调性:
- HNSW使用BF遍历时,会为维护一个ef大小的候选队列,设置E为ef,设置w为1
- 基于分区的索引中(多个聚类),第一阶段识别m个最接近的聚类,第二阶段遍历聚类中的向量,设置E为k,w为m个聚类中所有向量的总数
3.2 统一的查询执行引擎
VBase使用火山模型作为统一的执行引擎,对于传统索引不需要做任何更改,对于仅暴露TopK接口的向量索引,会进行简单适配,即暴露索引内部的Next、Close等接口。
另外添加了放松单调性的检查,仅在原始终止条件和放松单调性检查都通过时停止,具体而言:
- 对于OrderBy + Limit,除了收集k个向量,还有放松单调性检查为真
- 对于范围查询,当遍历的向量的距离超过R并且放松单调性检查通过时停止
统一引擎创造了优化机会,例如可以直接在遍历时执行过滤,具有灵活的终止条件。另外还可以支持向量连接。
3.3 结果等价性
此节将展示基于放松单调性的统一引擎的查询结果与基于TopK和临时索引方案的结果相等,并且相当于使用的是最优的k。
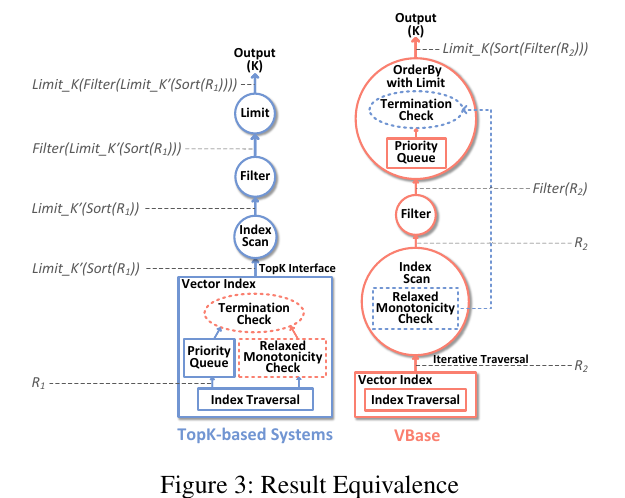
通过一些公式证明了结果等价性,具体可看论文原文。
4 VBase实现
4.1 放松单调性检查
准备两个队列:
- 大小为E的优先队列(smallestQueue)
- 大小为w的队列(recentQueue)
4.2 查询执行引擎
基于PostgreSQL,对向量索引进行了简单修改(HNSW、IVFFLat、SPANN),去除了不必要的状态,仅保留遍历功能。
4.3 查询计划
此节主要介绍具体的代价估算
4.4 多列扫描优化
普通轮询方式中,不同向量索引可能返回不同质量的结果。为此,提出了一种优化方法:
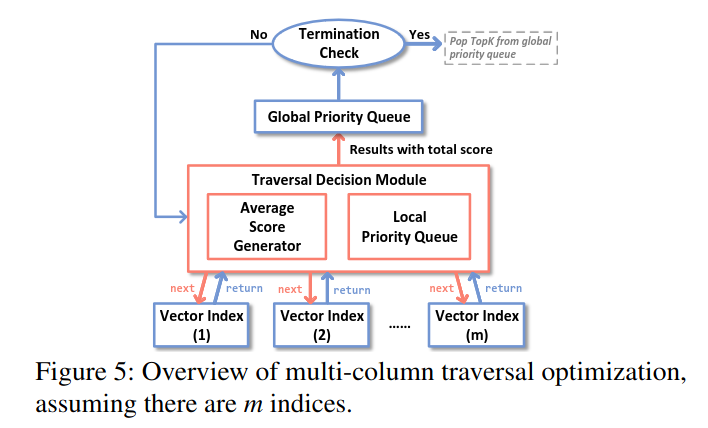
将遍历过程分为多轮,维护一个局部优先队列记录上一轮信息,帮助识别哪个索引会返回更好的结果,从而在下一轮更多地访问它。同时记录每个索引遍历的平均得分,并在每回合更新。
5 VBase评估
基于Recipe1M扩展了一组向量和标量混合的数据集,设计了7种SQL查询,用召回率和延迟作为指标,与多个向量数据库系统进行了比较,详情可见论文原文。