Amazon MemoryDB论文浅读
本文最后更新于 2026年6月15日 下午
论文为:Amazon MemoryDB: A Fast and Durable Memory-First Cloud Database.
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
1 Introduction
对于许多实时应用程序,如金融、广告和物联网(IoT)应用程序,快速响应时间至关重要,现代键值存储可以为每台机器提供每秒数百万次操作和微秒级延迟,具有简单的键值语义,但对于大规模数据缺乏扩展性。
Redis 提供微秒级的延迟,同时允许应用程序操作远程数据结构、执行复杂操作并将计算操作推送到存储。其对复杂共享数据结构的支持大大简化了分布式应用程序,并且是其受欢迎的主要原因。
然而 Redis 采用异步复制以实现高可用性和读取扩展,并使用磁盘上的事务日志来实现本地持久性。导致了其缺陷:
- 可以提供最终一致性,但无法提供强一致性
- 节点丢失的情况下可能丢失数据
异步复制是一种主从结构,数据的更改首先在主节点上执行,然后这些更改会异步发送给多节点,主节点在完成写入操作后并不需要等待从节点的确认,而是继续处理后续请求。其优点为可以更快的处理请求,缺点为存在数据丢失的风险,并且可能从副节点上读到过时的数据(详见2.2)
而本文主要介绍 Amazon MemoryDB 系统,作为一种基于云的内存数据库服务,专门为 Redis 设计并解决一致性问题,其优势为:
- 保持与 Redis 的完全兼容
- 提供强一致性和高可用性
- 几毫秒写入延迟和微秒级读取延迟
其使用 Redis 作为内存执行引擎,并使用一个专门的事务日志服务进行数据持久化操作。
2 Background and Motivation
2.1 Background on Redis
Redis 支持多种命令和数据结构,包括 hash tables、sorted sets, streams, and hyperloglog 等,一组命令可以保持原子性,要么全部成功,要么全部失败。同时还支持在服务器端执行 Lua 脚本,这些脚本也保持原子性。
hyperloglog是一种基数估计,可以用很少的存储空间来估计非常大的数据集的不同元素的个数(基数)
Redis 支持水平扩展,使用CRC16将其平坦的键空间划分为16384个槽,让不同的集群负责存储不同的键(分片机制),每个分片集群有一个可写入的主节点和多个只读的副节点,客户端可从任何节点得到配置信息(槽到分片集群的映射)从而直接向对应的集群发送命令。为了实现最大性能,Redis 不负责命令的重定向,而是发送重定向指令并由客户端负责处理。分片机制可以扩展服务的并发能力。
MemoryDB 支持原子级的分片迁移,并且能保证在迁移时正常处理请求(详见5.2)
另外在 Redis 的异步复制中,允许非确定性操作以确定性方式进行复制,例如SPOP命令,它会从集合中随机移除一个元素。当在主节点上执行此命令时,会随机选择集合中的一个元素,然后,针对所选元素的显式删除命令会通过复制通道发送到副本。对于脚本操作也是如此。
2.2 Challenges of Maintaining Durability and Consistency in Redis
Redis 虽然通过时间点快照和磁盘日志来实现一些轻量级持久化机制,但当主节点发生故障时,会选出新的主节点,不同于 Raft 协议,并不保证新的主节点包含最新的数据,可能造成数据丢失。
另外,虽然 Redis 提供了 WAIT 命令,进行强制执行同步复制,集群会被阻塞直到被收到所有副本确认已执行先前的所有命令,但并不能阻止其他客户端访问其他副节点读到旧数据。
综上所述,尽管 Redis 在保持高可用性方面表现良好,但仍然存在问题,需要一种解决方案,以便将 Redis 用作分布式持久性的主数据库,同时最小化性能的影响,减少与 Redis 代码库的偏离,并支持与 Redis API 的完全兼容性。
3 Durability and Consistency
3.1 Decoupling Durability
首先针对持久性:
一个持久化数据库系统必须确保一旦数据被提交并确认,就可以被读取。常见的日志记录和复制策略提供的持久性水平通常与可用数据库集群节点数量有关。
为了最小化与 Redis 的差异,MemoryDB 将执行引擎(Redis)与持久性层解耦,架构如图所示:

使用 Multi-AZ Transaction Log (多可用区事务日志服务,其中多可用区理解为多个区域,区域间通信延迟低并且互相不受故障影响)作为持久性层。
使用 Redis 作为内存中的执行和存储引擎,但将其现有的复制流重定向到持久性层,该层负责将写入操作传播到副本并进行主节点选举。这能够在不对引擎进行侵入性修改的情况下提供完整的 Redis API,因为利用了相同的复制策略。
具体而言,MemoryDB 拦截 Redis 的复制流,将其分块为记录,并将每条记录发送到事务日志。副本从事务日志中顺序读取复制流,并将其流入 Redis。因此,每个副本都持有数据集的最终一致性副本。
而内部的 AWS 事务日志服务提供了强一致性、跨多个可用区(AZ)的持久性和低延迟。写入日志的操作只有在持久性地提交到多个 AZ 后才会被确认。
由于持久层的解耦,所以可以独立于内存引擎进行扩展,从而可用性成本可以独立于持久性成本进行调整(存算分离)。例如仅使用主节点或主节点加一个副本进行操作,但仍然能够在三个 AZ 中获得持久性,这在计算和存储耦合的情况下是无法实现的。
3.2 Maintaining Consistency
针对一致性:
Redis 是单线程的,并且按顺序执行它接收到的所有命令;然而,由于其异步传播,它可能会在故障转移期间丢失已提交的写入。所以需要将操作传到事务日志层,此处使用了后写日志(WBL)的方式,在操作结束后生成日志信息传入事务日志层。相对于预写日志(WAL),可以让非确定性命令以确定的方式复制(前文所述的 SPOP 命令)
而由于是后写日志,变更在提交到事务日志之前会在主节点上执行。但如果提交失败,例如网络隔离,则该变更不得被确认,也不得变得可见。但是由于已经在主节点上执行了,对于其他数据库引擎可以使用隔离机制(例如MVCC)来实现这一点,但 Redis 数据结构不支持此功能,并且无法轻易与数据库引擎本身解耦。
为解决这个问题,MemoryDB 添加了一层客户端阻塞,客户端发送操作后,其回复会存储在跟踪器中,直到事务日志确认持久性后才发送给客户端。而主节点并不会阻塞,仍会处理其他操作,但是必须咨询跟踪器来判断是否有尚未持久化的操作。
跟踪器是在键的级别的,如果某个键的值或数据结构已被尚未持久化的操作修改,则对该键的读取操作的响应会被延迟,直到该响应中的所有数据都被持久化。而副本节点不需要阻塞,因为变更只有在提交事务日志后才可见。
这样,同时提供了主节点的强一致性数据访问,以及副节点的最终一致性访问,并且还可以跨多个节点读取,例如在多个副本之间负载均衡读取。
4 Availability, Recovery and Resilience
4.1 Leader Election
Redis 集群属于 Leader-Follower 的类型,采用基于多数的仲裁机制(类似于 Raft 中的 Majority)。使用 gossip 协议作为集群总线,主节点通过集群总线不断发送心跳。
其中 gossip 协议是一种通信协议,采用了类似于留言传播的方式实现信息在节点间的快速传播,其主要特点包括对等通信、随机通信、概率传播、最终一致性。
当大多数节点未收到某个主节点的心跳时,该主节点被声明为失败,随后大多数节点将投票选举一个失败主节点的副本。由于 Redis 在访问或更新数据时不使用共识,因此没有保证被选举的副本观察到了所有已提交的更新。例如,如果一个主节点与集群的其他部分隔离,它会继续提供数据服务,直到达到某个超时,副本可能会被提升。
实际上,Redis 未能满足基于仲裁的复制系统的一些安全属性:
- 领导者唯一性:在任何给定时刻,最多只能有一个领导者在运行
- 一致的故障转移:只有一致的副本才能竞选并赢得领导权。
为此,MemoryDB 利用事务日志来构建领导者选举:
- 确保只有完全同步的副本才有资格被提升为主节点,从而在故障发生时保持强一致性
- 利用租约系统来确保领导者唯一性,自动降级失败的主节点
由于不需要利用执行层的集群来维护选举,因此在可用性上优于 Redis 集群总线的领导机制。
4.1.1 Building atop the Transaction Log.
首先让每个日志条目都有一个唯一的标识符,并且每个追加请求必须指定它打算跟随的条目的标识符作为前提条件(类似于 Raft 中的一致性检查)。获取领导权是通过将特定的日志条目追加到事务日志中来实现的。
4.1.2 Consistent Failover.
主节点故障时,多个副本开始争夺领导权,开始追加特定的日志,此时只有拥有最新日志的副本才能成功追加,并且只能有一个会成功,并且使任何其他并发追加请求失效,从而确保数据不会丢失,保证一致性。
这样,MemoryDB 的领导者选举绕过了 Redis 集群总线。它不需要运行的多数或最小节点数。每个副本只与事务日志服务交互,而不与彼此交互。只有在新主节点被选举后,角色变化才会通过集群总线异步传播,以通知集群中的其他节点。其余节点可以利用此信息通知客户端角色变化,以实现最小的停机时间。
4.1.3 Leader Singularity.
通过租约的方法确保领导者的唯一性,具体而言,领导者定期将租约续订日志追加到事务日志中来(相当于替换心跳机制),副本观察到租约续订后会启动本地的计时器(类似于 Raft 的选举超时),确保计时器时间严格大于租约持续时间,在此期间不会争夺领导权。
而一个无法续订租约的主节点(遇到网络故障)将在租约结束时自愿停止提供读取和写入服务。当副本节点在回退时间段后未观察到事务日志中的任何租约续订条目时,它们将恢复争夺领导权的尝试。
综上所述,通过这种方式:
- 集群仅依赖于事务日志服务的可用性,而不是多数节点的额外可用性
- 主节点无法保持其租约,它会自我降级以防止提供过时数据,从而避免脑裂
- 副本在未观察到事务日志中的所有更新之前,无法争夺领导权,从而避免数据丢失
4.2 Recovery
前文描述了故障发生时如何保持一致性和可用性,此节描述如何进行故障恢复。
MemoryDB 使用监控服务(详见第5节)不断轮询所有 MemoryDB 副本以监测其健康状态。该服务是独立于数据节点的,其轮询结果形成了集群连接性和健康状况的外部视图。
此外,同一集群中的节点之间也会不断进行信息交换,以形成集群连接性和健康状况的内部视图。
在判断故障时,会同时参考外部视图和内部视图,以提高故障检测的准确性。一旦确定某个节点已失败,监控服务将采取措施进行恢复。根据故障模式,数据库进程可以在原地重启,或者更换底层硬件。新节点总是以副本的身份启动。
4.2.1 Data Restoration
首先是数据恢复,我们利用 Redis 现有的、经过验证的数据同步 API,让恢复中的副本加载最近的时间点快照,然后重放后续的事务。
虽然 Redis 需要主节点的存在才能恢复先前存储的数据,但 MemoryDB 定期创建快照并将其持久存储在简单存储服务(S3,AWS提供的一项对象存储服务)中。这使得 MemoryDB 能够在没有主节点的情况下恢复已提交的数据。恢复中的副本从 S3 获取并加载最新的快照,然后从事务日志中重放。
因此,数据恢复成为一个局部于恢复副本的过程,它们不会与任何可用的同伴进行交互。此外,这一过程允许多个副本并行恢复,而不会出现任何集中式的扩展瓶颈。S3 和事务日志是独立扩展的,能够允许所有副本同时恢复数据。
4.2.2 Off-box Snapshotting
Redis 通过建立额外进程,利用写时复制的技术进行快照建立,但这一操作会增加整体内存使用,并且由于是计算密集型,会提升读取操作的延迟,也可能会在主节点故障时延迟恢复过程而影响可用性。
为改善这一过程,MemoryDB 构建了离线快照创建。通过离线集群(对客户端不可见的临时集群),与客户集群共享相同的持久数据源(S3 和事务日志),以便能够代表客户创建快照,并且 S3 和事务日志的扩展能够容纳来自离线集群的额外读取工作负载。

这些离线副本使用和客户副本相同的数据恢复程序进行引导。如图,即先恢复 S3 中最新生成的分片快照,然后重放事务日志,直到离线集群创建时记录的尾部位置,然后停止。这重新创建了一个静态数据视图,反映了客户集群的最近状态,并保证比任何先前的快照更新。然后,每个离线副本将其数据视图转储到一个新快照中并上传到 S3。根据设计,离线副本不属于客户集群,因此不受客户流量的影响,并能够充分利用其可用的 CPU 和内存资源进行快照创建,而不会干扰。
4.2.3 Snapshot Creation Scheduling
由于创建快照会消耗大量计算资源,MemoryDB 的快照创建调度努力在新鲜度和成本之间取得平衡。快照的新鲜度可以视为其与当前事务日志尾部的距离。快照越新鲜,恢复副本重放事务日志所需的时间就越少,从而使潜在的数据恢复更加以快照为主导和高效。
快照新鲜度下降的速度取决于客户的写入吞吐量和客户数据集的大小。更高的写入吞吐量会更快地增加快照与事务日志尾部的“距离”。更大的数据集大小会使创建新快照所需的时间更长,并间接允许事务日志增长。
MemoryDB 监控服务持续对实时集群上的这些数据进行采样,根据这些因素计算快照的新鲜度,并在新鲜度过于陈旧时调度新的快照创建。
5 Management Operations
5.1 Cluster Management
然后是集群管理部分,使用控制平面负责处理客户的资源配置请求,并执行集群更新和升级,包括协调扩展活动。控制平面还负责通过快速诊断和修复集群级别的故障来维护 MemoryDB 的高可用性。
控制平面是一个区域性的多租户服务(在特定地理区域内,为多个租户提供共享的基础设施和服务),代表客户管理一组单租户集群。
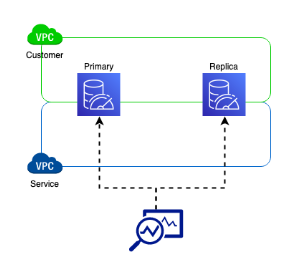
如图,MemoryDB 客户集群通过客户提供的虚拟私有云(VPC)进行访问。MemoryDB服务使用另一个 VPC 与客户集群进行交互。
每个创建新 MemoryDB 集群的请求都会配置指定数量的 Amazon EC2 实例(虚拟机云服务)和所需数量的多可用区(Multi-AZ)事务日志,然后将节点配置为请求的拓扑结构。控制平面使用适当的 AWS 密钥管理服务(KMS)密钥(可以是客户拥有的或服务提供的)采用信封加密策略(即,明文数据与数据密钥,然后将数据密钥加密在另一个密钥下)来加密 MemoryDB 节点本身和多可用区事务日志上的静态数据。
在集群创建请求期间,客户提供一个虚拟私有云(VPC)。当客户创建至少有一个副本的分片时,节点会被放置在不同的可用区(AZ)中,以确保在单个可用区故障的情况下没有停机时间。控制平面负责将集群的节点附加到客户的 VPC,提供稳定的 DNS 端点指向这些节点,必要时发放 TLS 证书,以及将访问控制列表(ACL)等配置推送到每个节点。这些活动在集群范围内协调,并根据需要在分片或节点之间并行化。
控制平面协调补丁和扩展等操作。MemoryDB 采用滚动 N+1 升级过程,而不是传统的蓝绿部署策略(维护两个完全相同的生产环境来实现无缝的版本升级和回滚):在升级过程中,不是就地升级节点,而是配置运行新软件的新节点,进行逐步升级。这通过允许所有节点在升级期间继续提供流量来减轻对集群可用性的影响。
同样,扩展集群的过程涉及添加一个由新节点组成的新分片,并逐步将 Redis 槽从现有分片移动到新分片。这个过程是集中协调的,更多细节将在第 5.2 节中讨论。
监控服务每 5 秒从集群中的所有节点获取数据,以了解集群的健康状况。它充当集群配置的看门狗,修复有效的配置(例如,检测到的故障副本),并对无效的配置(例如,分片中只有一个副本)发出警报。
5.2 Scaling
MemoryDB 集群的大小可以从三个维度进行衡量:
- 分片数量(集群数量)
- 每个分片的副本数量(集群中节点数量)
- EC2 实例类型(所提供的CPU和内存)
控制平面API提供了在运行中的集群上动态调整这三个维度中的任何一个的能力,而不会造成显著中断。这些API可以手动或程序化调用。
副本数量扩展:
增加副本数量是最简单的操作。要减少副本数量,从每个分片中选择一个副本并终止,释放相关的 EC2 实例。要增加副本数量,则为每个分片创建并配置一个新的 EC2 实例。一旦新的 EC2 实例投入使用,它将从 S3 重新加载该分片的最新快照,然后重放其事务日志。一旦达到事务日志的末尾,该副本就会加入集群,并通过 Redis 集群总线广播其可用性。
实例类型扩展:
实例类型的扩展是通过N+1滚动更新进行的。使用上述程序创建新的实例类型的副本。一旦新的副本加入,控制平面将选择一个旧实例类型的节点(优先选择副本,最后选择主节点)进行退役,这会导致主节点退役的情况下进行领导者选举。通过协作领导转移,即旧实例主动交接领导权,可以最小化停机时间。如果新实例类型小于旧实例类型,可能会出现内存不足的情况,此时将撤销扩展操作,恢复原始实例类型。
分片数量扩展:
扩展分片数量需要在分片之间转移一个或多个槽,并在操作开始时创建分片(扩展)或在扩展操作结束时销毁分片(缩减)。分片的创建/销毁涉及到与副本扩展操作相同的节点的配置/终止,以及每个分片的事务日志的创建/销毁。分片扩展会涉及槽的转移,槽转移分为两个阶段:数据移动和槽所有权转移。
数据移动阶段在概念上类似于 Redis 副本同步,但仅限于特定槽,因此被转移的槽的键必须被序列化并从源主节点传输到目标主节点,同时继续允许可能会改变这些键的操作。因此,转移的数据包括序列化的键和已经传输的键的复制流变更。目标主节点将所有消息提交到事务日志,使其副本能够达到相同的状态。
在所有权转移可以启动之前,源主节点确保所有数据已被转移,然后阻止所有新的写入操作并等待任何正在进行的写入操作完成执行并传播到源和目标事务日志。此时将与目标进行数据完整性握手,以验证数据的正确转移——在此之前的任何错误(如内存不足、网络错误、验证失败等)都可以通过简单地放弃转移操作来轻松恢复,即恢复写入操作并指示目标删除所有转移的数据。
在 Redis 中,槽所有权通过最终一致的集群总线进行控制和通信。该机制已知存在多种故障模式,可能导致存储数据的损坏或丢失。以最大化与 Redis 的兼容性为原则,槽所有权的通信仍然是集群总线的责任。但同时,槽所有权存储在事务日志中,槽所有权的变更是通过使用2阶段提交协议在槽的旧所有者和新所有者之间进行持久化提交消息。一旦槽所有权转移,新所有者开始接受写入,而旧所有者则正确响应对移动槽的操作重定向,并开始以速率限制的后台任务删除所有转移的数据。
通常,在所有权转移阶段,槽的写入不可用的持续时间仅限于几次网络往返和事务日志更新延迟。源或目标的故障,例如由于租约到期,可以通过事务日志中记录的2PC进度进行恢复。在主节点故障(源或目标)恢复后,所有权转移协议可以继续进行。
绘制出如下图所示的架构帮助理解:
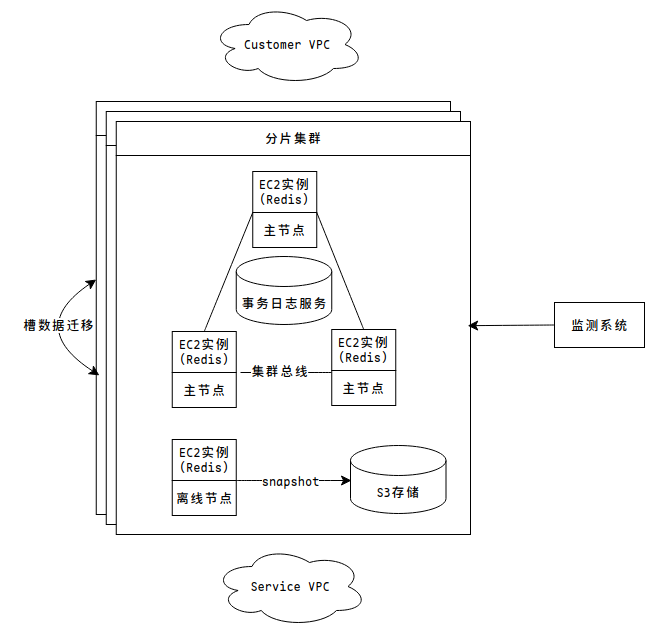
6 Evaluation
本节的目标是评估 MemoryDB 中的持久性成本。MemoryDB 的持久性有两个组成部分:
- 提交到事务日志的稳定状态写入
- 定期上传到 S3 的快照
为了评估稳定状态下的性能,我们使用基准测试来展示 MemoryDB 在不同类型工作负载下的性能特征。我们将开源 Redis 的 7.0.7 版本作为基准,设立 Graviton3 架构下(亚马逊自研的 ARM 架构处理器)的所有不同实例类型,与 MemoryDB 进行比较。之后,我们将重点关注快照组件,通过将 Redis OSS 的快照功能性能与 MemoryDB 专门构建的离线快照进行比较。
6.1 Performance Benchmark
6.1.1 Setup
我们测试了三种类型的工作负载:只读、只写和读写混合工作负载。
在只读工作负载中,每个客户端连续发送 GET 请求到 Redis 服务器(不使用管道)。在只写工作负载中,使用SET命令。在读写混合工作负载中,80%的请求是GET,20%的请求是SET。
我们使用 10 个 EC2 实例,每个实例运行一个 redis-benchmark 进程,以向 MemoryDB 和 Redis 发送流量。这 10 个 EC2 实例在与 MemoryDB 和 Redis 相同的可用区(AZ)中启动,以最小化网络延迟。
在测试之前,节点预填充了 100 万个键,以确保 GET 请求的命中率为100%。我们为每个 redis-benchmark 进程配置了 100 个客户端连接和 100 字节的值。我们使用简单的GET/SET操作来获得一致的性能基线,而不是使用较大的数据结构。
Redis 支持线程 IO,将 IO 操作卸载到后台线程。MemoryDB 支持增强 IO,这是一种类似的内部功能,允许引擎将 IO 卸载到后台线程。MemoryDB 增强 IO 具有更高级的功能,例如,它可以将多个客户端复用到一个连接中,从而减少 IO 的开销。我们为每种实例类型的 Redis 配置了与 MemoryDB 相同数量的 IO 线程。由于 Redis 不支持与 IO 线程一起使用的 SSL,因此我们禁用了 TLS 加密和身份验证。
6.1.2 Benchmark Result
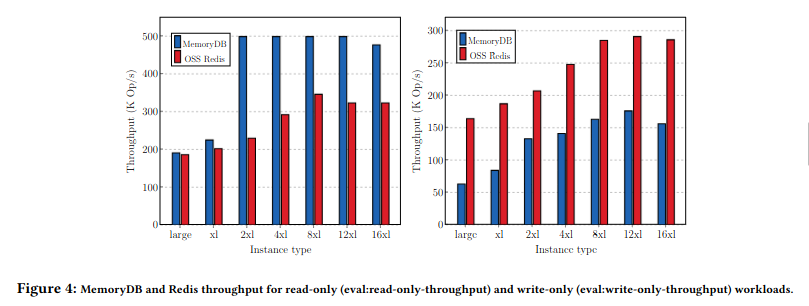
吞吐量评估:
上图展示了在不同实例类型下,针对只读和只写工作负载观察到的最大吞吐量。
-
对于只读工作负载,在2xlarge以下的实例类型中,Redis和MemoryDB的吞吐量相当,最高可达200K操作/秒。从2xlarge开始,MemoryDB的表现优于Redis,在所有实例类型中实现了500K操作/秒,而Redis的最大吞吐量为330K操作/秒。这表明MemoryDB在只读工作负载上表现良好。MemoryDB的增强IO复用功能将多个客户端连接聚合到一个连接中,从而提高了处理效率并提供了更高的吞吐量。
-
在只写工作负载中,我们可以看到Redis在所有实例类型上都优于MemoryDB,最大吞吐量接近300K操作/秒,而MemoryDB的最大吞吐量为185K操作/秒。MemoryDB将每个写操作提交到多可用区(multi-AZ)事务日志,导致请求延迟更高。在相同的工作负载下,客户端发出顺序阻塞请求,因此MemoryDB在只写工作负载上的吞吐量低于Redis。在客户端数量较多、使用管道或较大负载的工作负载下,我们的实验表明,MemoryDB的单个分片可以实现高达100MB/s的写吞吐量。
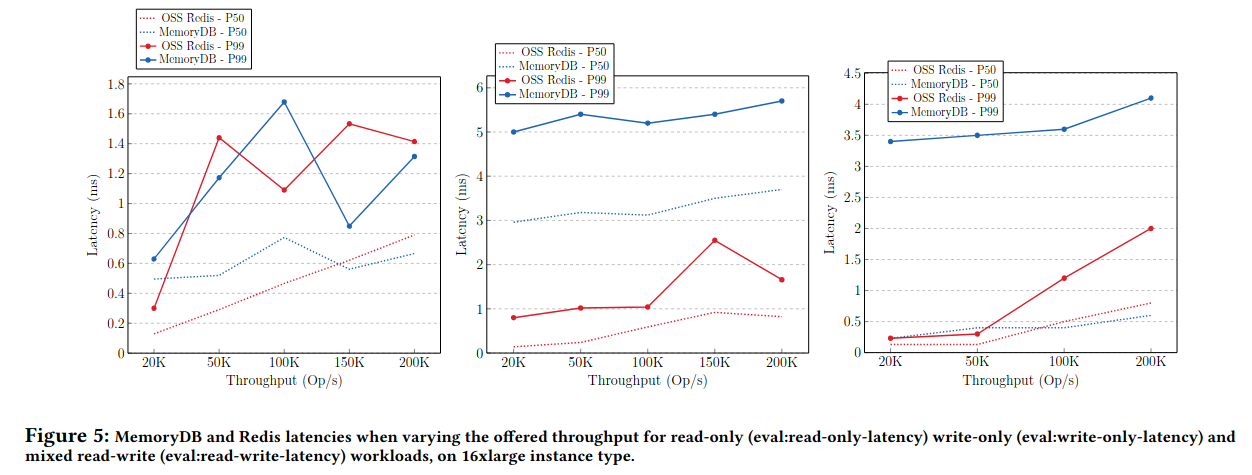
延迟评估:
上图显示了在16xlarge实例类型下,Redis和MemoryDB在不同工作负载下的延迟情况,随着提供的吞吐量变化。
- 对于只读工作负载,Redis和MemoryDB的延迟特征相似,p99小于2毫秒(p99表示百分之99的情况下都会在这个时间内得到响应)。
- 对于只写工作负载,Redis提供亚毫秒的中位数延迟,p99延迟最高可达3毫秒,而MemoryDB的中位数延迟为3毫秒,p99延迟最高可达6毫秒。
- 对于混合读写工作负载,Redis和MemoryDB均提供亚毫秒的中位数延迟,Redis的p99延迟最高可达2毫秒,而MemoryDB的p99延迟最高可达4毫秒。
这表明MemoryDB在读和混合读写工作负载中提供亚毫秒的中位数延迟,在只写和尾混合读写工作负载中提供单数字毫秒的延迟,同时确保每个写操作的持久性。
6.2 Snapshot Evaluation
Redis会fork一个子进程来执行快照。这个子进程通过遍历整个键空间来创建数据库的时间点快照,并将数据序列化到磁盘。在这个序列化过程中,如果Redis(父进程)修改了内存页,就会发生写时复制(COW),导致内存页被复制,以便子进程的相应内存页保持不变。COW在重写负载较重时可能导致过多的内存被积累。在最坏的情况下,这可能会使内存消耗翻倍,从而导致高交换使用,造成显著的延迟增加和吞吐量下降。
此节将评估两个问题:BGsave的开销在哪/离线快照的开销在哪
为了设置实验,我们使用一个具有2个vCPU和16GB RAM的实例。最大内存配置为12GB。数据预填充了2000万个键,每个键值对为500字节。我们使用比第6.1.2节更大的负载大小,以更快地增加内存压力。100个客户端发出GET命令以测量吞吐量和延迟,而另外20个客户端发出SET命令。
当快照过程正在运行时,我们记录平均吞吐量以及平均延迟和p100延迟。
6.2.1 BGsave

上图展示了COW对Redis的延迟和吞吐量影响的评估。当BGSave开始时,吞吐量没有影响。然而,p100延迟出现了高达67毫秒的峰值。这是由于fork系统调用克隆了整个内存页表。根据我们的内部测量,这个过程大约需要12毫秒每GB内存。一旦实例耗尽所有DRAM容量并开始使用交换来分页内存页,延迟就会增加,吞吐量显著下降。这是因为CPU在等待将内存页溢出到磁盘之前被阻塞,无法继续执行COW。尾延迟在一秒内增加,吞吐量接近0,因为交换超过了总内存的8%,这在客户的角度上实际上是可用性中断。
为了在实践中防止这种情况,Redis的用户需要将数据库可用内存减少到主机可用DRAM的一半,以防止写负载将系统驱动到交换并造成可用性影响,或者在写流量很少的非高峰时段运行快照。
6.2.2 off-box
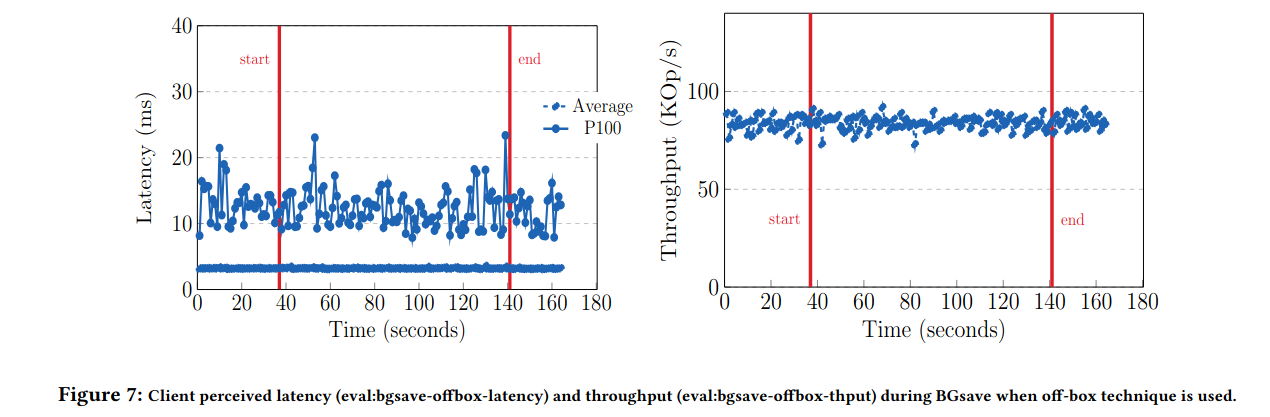
MemoryDB在离线集群上执行快照。上图描绘了在离线集群快照过程并行运行时MemoryDB集群的吞吐量和延迟。我们观察到平均延迟保持在1毫秒左右,而最大延迟在10毫秒到20毫秒之间。
p100的值比第6.1.2节中报告的数字高,因为我们在快照时运行的是混合读/写负载,值大约是5倍,并且尾读延迟会受到提交延迟的影响(即,如果读取尝试访问未提交的键)。
当快照开始时,我们观察到吞吐量和延迟在整个过程中保持稳定,并且在结束后也没有变化。由于离线过程启动了一个与客户集群隔离的集群,因此在MemoryDB中快照期间不会对客户工作负载产生影响。因此,MemoryDB客户无需为快照保留任何内存容量,也无需担心在非高峰时段协调快照。
7 Consistency During Upgrades
如前所述,我们使用N+1滚动升级策略来在升级过程中保持可用性。在此升级过程中,首先升级副本节点,最后升级主节点,以保持读取吞吐量的能力。为了保持可用性,我们无法强制所有节点同时以事务方式升级。因此,正在进行升级操作的集群在过渡期间可能会有混合版本。这可能导致不一致。例如,运行较新引擎的主节点可以将新引入的命令发送到事务日志,而运行较旧引擎的副本节点观察到这些命令,在最坏的情况下可能会误解这些命令。
为了解决这个问题,我们开发了一种升级保护机制。我们通过指示哪个引擎版本生成了复制流来保护复制流。如果运行较旧引擎版本的副本节点观察到来自当前运行的较新版本的复制流,它将停止消费事务日志。
另外为了确保集群在升级过程中即使在发生故障时也能保持可用性,控制平面协调离线进程,以便在集群中运行的最旧引擎版本上进行快照。这使得仍在运行旧引擎版本的节点在升级过程中发生故障时能够被替换。
8 Related Work
许多分布式数据库已经采用存算分离的架构。
基于日志的复制已经被广泛应用于共识算法以及分布式存储系统,作为提供持久性的一种方式(multi-paxos、raft)。
许多关系数据库使用内存作为其主要存储介质以提高性能,Redis作为最受欢迎的内存存储系统之一,因其丰富的数据模型而脱颖而出。然而,由于其较弱的持久性保证,用户很难将Redis作为其主要数据库。MemoryDB是一种云原生的基于内存的数据库,提供强一致性、11个9的持久性和4个9的可用性。
9 Conclusion
本文介绍了亚马逊MemoryDB,这是一种快速且持久的基于内存的云存储服务。MemoryDB的核心设计是通过利用内部AWS事务日志服务来解耦持久性与内存执行引擎。通过这样做,MemoryDB能够将一致性和持久性问题与引擎分开,从而独立扩展性能和可用性。为此,一个关键挑战是确保在所有故障模式下的强一致性,同时保持性能和与Redis的完全兼容性。MemoryDB通过拦截Redis复制流,将其重定向到事务日志,并将其转换为同步复制来解决这个问题。MemoryDB在事务日志之上构建了一个领导机制,以强制执行强一致性。MemoryDB为客户解锁了新的能力,使他们在使用Redis API时不必在一致性或性能之间做出妥协,而Redis是过去十年中最受欢迎的数据存储之一。