Self-Tuning Query Scheduling论文浅读
本文最后更新于 2026年3月19日 下午
论文为:Self-Tuning Query Scheduling for Analytical Workloads
sigmod 2021
https://15721.courses.cs.cmu.edu/spring2024/papers/08-scheduling/wagner-sigmod21.pdf
1 Introduction
本文提出一种自适应的调度优化策略,在高负载下的查询分析系统中,仍能保证足够低的查询延迟。(尤其是短时间运行的请求)
与postgresql(直接使用操作系统的调度,限制最大进程数)的一个对比如下:
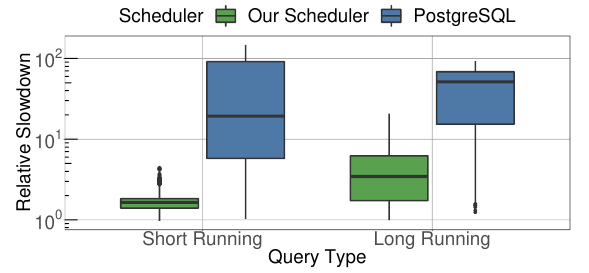
纵坐标是相对的查询延迟变化,可以看到本文提出的调度方法在高负载下的延迟提高更少。
许多现代数据库系统都开始使用自己的调度方法,将每个查询拆分为一组独立的任务,一些例子:
- SAP HANA使用自适应数量的线程,从不同的查询中选择任务
- Hyper和Umbra几乎将所有调度策略都由自己管理,在启动时生成cpu-core数量的线程
任务的并行化通过morsels实现(包含一组固定的元组,查询执行期间的最小工作单位)
像Intel TBB这样的通用任务调度器主要专注于最大化吞吐量,而数据库系统更应关注查询响应性等目标,使用更适合数据库系统的调度策略。
本文提出一种无锁化的自适应调度系统,应用在Umbra系统中。
2 Scalable Task Scheduing
该节重点介绍实现细节,使用stride scheduling(虚拟时间片),同时最小化线程通信成本(几乎所有的决策都是thread local的)
2.1 Background:
关于stride scheduling:
假设有任务以及对应的整数优先级
每个任务对应一个stride ,以及pass 初始化为0
选择pass最小的任务,执行一个时间片的工作,然后将其更新为
于是,优先级越高,被调度的频率越高,任务可以获得的计算资源
对于动态变化的任务集,如果在任意时刻添加任务,则需要一个初始化pass值
为此维护一个全局stride 和全局pass ,同样在每次调度时间片后,此时新加入的任务的初始pass即此时的(相当于调度器的全局时间戳)
如果一个任务的pass低于全局pass,则它尚未获得应得的资源,反之亦然
2.2 Scheduling in Umbra
Umbra系统中的任务结构如下:
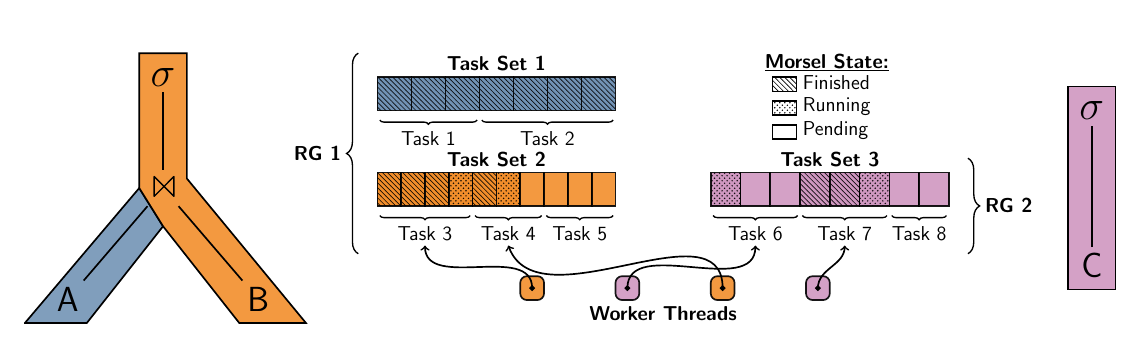
- pipeline 对应 task set
- task set 包含多个 tasks(morsels)
- one task bind to one thread
- 相同查询的 task sets 组成 resouce group(RG)
- task set 在 RG 中有序排列,同一 task set 中的 tasks 可以被并行执行
对于查询内和查询间的并行,使用morsels来驱动。但不同于Hyper(task和morsels 1:1映射),一个任务可以由任意数量的morsels组成,并且任务不是在查询编译期间静态创建,而是在运行时切割出task和morsel。
- 大大提高任务的灵活性
- 观察运行时任务结构变化
任务由线程执行,系统启动时会创建cpu cores的线程(工作线程),仅仅负责执行调度器任务。
- 最小化上下文切换
- 防止过度使用cpu
由于研究只考虑数据能在内存中存下的情况,所以线程几乎不会被io阻塞
单个线程的调度逻辑:选择一个active task set并切割出任务,然后执行。单线程不用感知并发操作。
2.3 Thread-Local Scheduling
由于现代cpu核数的增加,同步机制会造成更多性能损失。对于DBMS来说更需要让调度开销微不足道,本节介绍一种新的基于任务的stride scheduling实现。(原版的调度需要靠同步机制维护pass、stride)
新的设计可以在thread-local的基础上执行所有调度策略,线程仅在task set发生变化时被通知,这最小化了线程间的同步开销
另外对resource group数量设置了上限(128),新到达的查询的resource group会被放入一个等待队列,直到有空闲槽位
接下来讨论核心模块,注意虽然系统使用了stride scheduling,但也可以轻松修改为其他调度算法,只需要改变线程本地的调度逻辑即可。
Thread-Local Decisions:
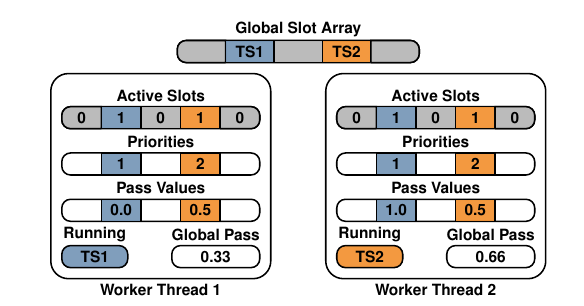
维护一个global slot array,每个槽位存放当前的active task sets指针,当一个资源组的task sets完成并且一个新的task sets变为active时会放入同一个槽位(相当于一个槽位对应一个资源组)
除此之外,所有调度元数据会以线程本地的方式存储,包括槽位的位掩码、优先级、pass值。然后每个工作线程存储自己的全局pass。
线程选择具有最小pass的活动槽,然后在全局槽上执行原子读取获取当前task sets的指针,然后选择一个任务,跟踪执行时间并相应的更新线程本地的pass值。该协议非常轻量级,所有核心调度策略都可以独立于其他线程执行。全局槽数组仅在新的task sets激活时写入,这些写入相对不频繁,不会导致过多的缓存失效。
但是替换任务集时仍需要同步,现考虑三种情况:
- 一个task set中的任务已经完成
- 空槽位插入了新的资源组的task set
- 槽位上的task set被替换为下一组task set
对于情况1,此时全局槽将其标记为无效,这样就不需要通知所有工作线程,而等线程再次去领任务时发现已经无效,然后再更新本地槽位为非活动
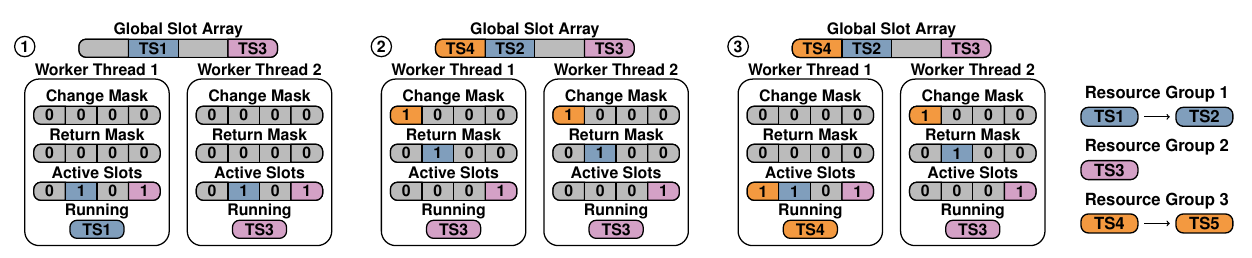
对于情况2/3,维护两个原子掩码位change mask / return mask(如下图),当发生情况2时,更新change mask,当发生情况3时,更新return mask。做出这样区分的目的是,优先级和pass值是和资源组绑定的,也就是情况2需要赋予新的优先级和pass值,而情况3不需要。
更新推送给所有线程,线程在领取任务之前,都会先检查一遍change mask和return mask,让mask与active slots做或运算,再重置mask,从而更新本地的active slots
下图是一个示例
现考虑任务集最终化,当任务集完成后需要激活下一个任务集,同时允许在任务集完成后运行额外的最终化步骤。
然而不能立即开始最终化,需要等待所有的线程完成最后的工作。为此,让第一个发现任务集中的任务领完后的线程负责协调最终化阶段,设置最终化标记位,然后遍历任务集找到目前在运行此任务集任务的所有线程,然后增加计数器,当这些线程完成工作后会检查标记位来判断是否进入最终化阶段,然后递减计数器。将计数器设置为0的线程负责执行最终化的任务,然后激活下一个任务集
3 Robust Morsel Scheduling
本节介绍了针对morsels系统的调度的进一步优化
3.1 Adaptive Morsel Execution
在hyper中,一个morsel对应一个任务,并使用固定大小的morsel,然而这种方式在morsel的持续时间方面存在不确定性,因为不同pipeline的代码的复杂性可能有很大差异。另外morsel的固定大小也是一个因素,如果太小会导致高调度开销,如果太大可能导致长时间阻塞
下图是一个例子,morsel的持续时间差异相差30倍:
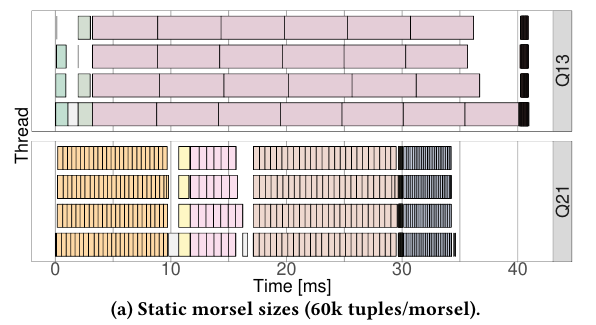
为了克服设计的局限性,引入了一种自适应任务执行框架。首先定义一个目标持续时间,当工作线程选择一个任务时,会尝试调度尽可能精确的耗尽这个持续时间。一个任务可以根据当前pipeline的吞吐量使用自适应morsel大小,也可以执行多个morsels。umbra系统中将设置为2ms。
会根据pipeline的执行进度,采用不同的策略。默认状态下,会选择一个完全耗尽的单个morsel,其大小为,其中是吞吐量估计。一旦morsel执行完成,就知道其实际执行时间,然后测得的吞吐量被纳入估计,设置的最新吞吐量为,在umbra系统中,取
然而获得初始的吞吐量估计并非易事,为此设置一个初始启动状态,当线程选择此pipeline中的任务时,首先运行一个包含个元组的morsel,之后运行的指数增长。假设已经执行了大小为的morsel,现在想调度一个大小为的morsel,可以预期,需要保证,如果无法满足这个条件,就切换到默认状态,最后一个启动morsel的测得吞吐量用作初始吞吐量
除了上述的两种状态外,还引入了一个关闭状态,通过剩余元组的数量和当前吞吐量估计来估算pipeline的剩余执行时间。如果调度器有个线程,当预测剩余时间小于时就会进入关闭状态。给定估计剩余时间t和最小的morsel持续时间,修改调度的morsel的持续时间从改为,这样的目的是为了最后尽量让每个线程都能平均地执行任务,避免线程闲置。另外,对于一些不支持自适应morsel大小的任务,如果发现执行一个morsel仅消耗目标持续时间的一部分,则允许其执行更多的morsels直到可以耗尽
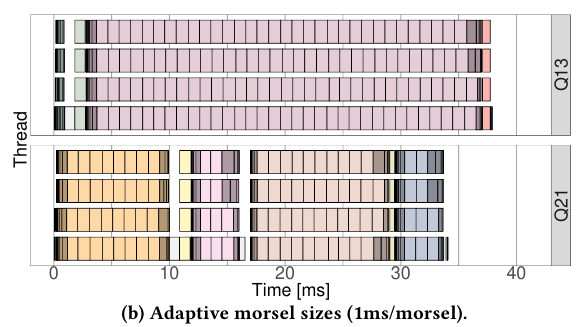
使用自适应框架得到的结果如下图所示,可以看到减少了Q13的查询延迟,关闭状态减少了线程闲置:
3.2 Adaptive Query Priorities
本节介绍自适应查询优先级,保证优先处理短时间运行的请求,而不需要用户手动提供优先级输入。
由于没有用户输入,首先假设所有查询的重要性相等,然后提出两个原则:
- 查询延迟在负载下应该保持可预测,给定一个查询,将定义为在独立执行时的延迟,对于工作负载,由元组组成,表示在时间下到达,对于表示使用调度策略在工作负载下的延迟,对于同时到达的两个查询,需要满足如果,那么
- 查询延迟应尽可能低,设为满足上述条件的策略,定义一个成本函数,即希望最小化 the mean relative slowdown of queries
优先执行短时间运行的查询不会显著影响其他长时间运行的查询的延迟,例如对于某种工作负载,10ms的查询占90%,1s的查询占10%,即使优先处理所有的短查询,也仅占整体工作负载的不到10%,但改善了九成查询的延迟,从而使得成本降低
前面说过,是优先级是绑定资源组的,其会被分配一个初始优先级,如果线程在其上花费的时间越多,其优先级就越低。具体而言,在资源组获得固定的CPU时间量t后(一般为,这样衰减通常在每个调度任务后发生)就更新其优先级:
其中定义了优先级开始衰减的时间,衰减的速度由调节,并保证优先级不能低于,控制这三个超参数来让成本函数最小化。但这些参数也依赖于工作负载,第四节将介绍自调优的优化器。
与公平调度相比,这种方式导致了更为偏斜的性能差异,但是能让短时间运行的查询延迟更低。
进一步也可以提供自定义优先级:
- 指定部分查询拥有静态优先级而不衰减
- 优先级也可以附加到用户上,用户优先级会影响该用户所有查询的衰减参数
4 Self-Tuning Scheduler
本节展示如何让调度器自我调节来动态改变衰减参数,以最大化查询性能。具体而言,会在固定时间间隔内跟踪工作负载。
考虑动机,对于由10ms和100ms的查询,可以在几ms后衰减,然而对于1s和10s的查询,所有请求都会很快达到最低优先级,短查询不再被优先处理。这种情况下希望显著增加衰减开始时间。
可以考虑为一个约束优化问题,首先固定初始优先级为并设置,定义参数空间:
对于某个 ,设表示具有优先级衰减参数的步幅调度策略。给定工作负载,我们尝试通过解决以下问题来找到最优参数:
实际就是最小化之前提到的成本函数
由于无法提前知道工作负载,所以在固定持续时间内跟踪正在执行的查询,然后用跟踪到的工作负载来解决优化问题,另外还定义一个刷新时间,在后开始一次跟踪运行。只跟踪单个线程上的执行情况,完整的迭代如下图所示:
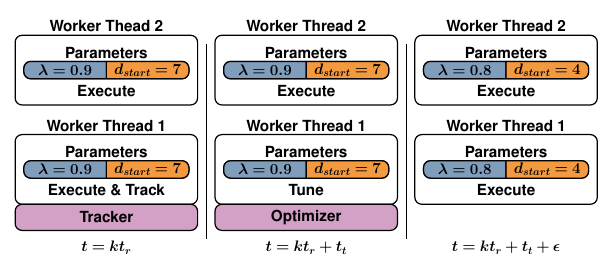
对于某一次迭代,首先将一个轻量级tracker附加到一个工作线程上,仅记录每个活动资源组上花费的执行时间,在持续时间后将不再执行任何任务,而使用跟踪到的工作负载进行参数优化。这不会影响到其他工作线程,一旦优化完成,新参数将推送到所有工作线程。在时间时会开始新的跟踪运行
为了进行参数优化,需要评估成本函数,为此对于选定的参数s,通过系统模拟获得模拟的查询延迟,模拟可以保持非常轻量级,因为第三节的自适应morsel执行确保了执行时间的可预测性。
由于调度的离散性质,给定在第k次跟踪运行后的工作负载,选择一组起始值,如果则设置,之后的跟踪使用上一次跟踪运行的最佳参数作为起始值。然后选择多个,确保的被跟踪的morsels能够没有延迟地执行。这可以通过对被跟踪的查询按照持续时间排序来计算。
然后对于每个选择的,通过局部搜索程序来细化,定义步长和搜索方向,评估所有点在上的成本函数,如果所有点的成本都大于,则设置,否则,更新为成本最小的值,
虽然这种优化方式看起来有些粗糙,但是在实践中效果很好,经验性的选择反而提供了更稳定的参数优化。而更复杂的优化器将留给未来工作。通过选择在一个有20个线程的系统上,找到最佳参数需要20ms~100ms,消耗的总处理时间不到0.01%。总体而言,这提供了一种轻量级的自调节调度器设计,能够适应工作负载的变化。
5 Evaluation
5.1 Experimental Setup
文章提出的调度器旨在很好地处理混合分析工作负载,这些工作负载由执行时间差异较大的查询组成。为了创建一个具有挑战性的实验设置我们在不同时间点向系统发送各种查询。由于工作负载应在低负载和高负载之间波动,我们通过从期望值为的指数分布中抽样来计算查询的间隔。通过这种方式,我们可以控制每秒个查询的到达率。通过不均匀地间隔查询,我们获得了动态工作负载波动,短时间内会有一批查询到达。为了获得长短运行分析请求的混合,我们从TPC-H查询的SF3和SF30中抽样,整个评估过程中,选择SF3的查询是SF30的查询的三倍
通过计算平均查询时间d,可以选择。例如如果目标负载为0.95并获得平均查询持续时间为100ms,则选择。我们将主要考虑负载因子范围
实验在一台Linux 5.3系统上运行,cpu是i9-7900x,10个核心,20个硬件线程,128G主内存
5.2 Comaprison Within Umbra
本节比较umbra系统中的不同调度算法,由于希望专注于不同算法的运行时特性,因此所有查询都是预编译的。使用公平调度(即本文提到的调度器,但使用固定优先级)和FIFO作为基准测试,作为参考,还包括了umbra的原始调度器,试图在尽可能公平的情况下最小化工作线程在任务集之间的切换。
设置查询时间总共五分钟,设置不同的工作负载,即使是最低的负载,也会导致大约3000个查询。下图展示了增加负载时查询延迟的变化,纵坐标是查询延迟的几何平均。
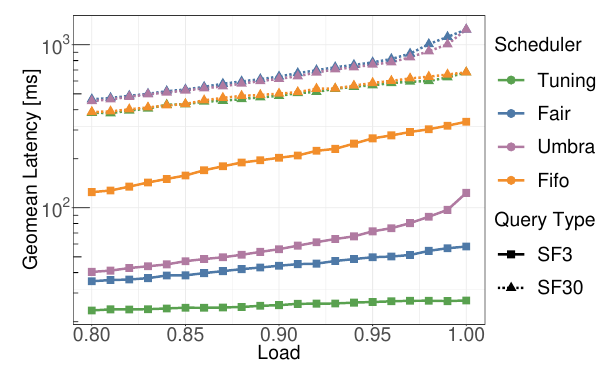
可以看到我们的自调节调度器在工作负载增加时仍能保证较为稳定的查询延迟,而FIFO的调度是极其不理想的。
现关注单个查询的延迟分布,如下图所示
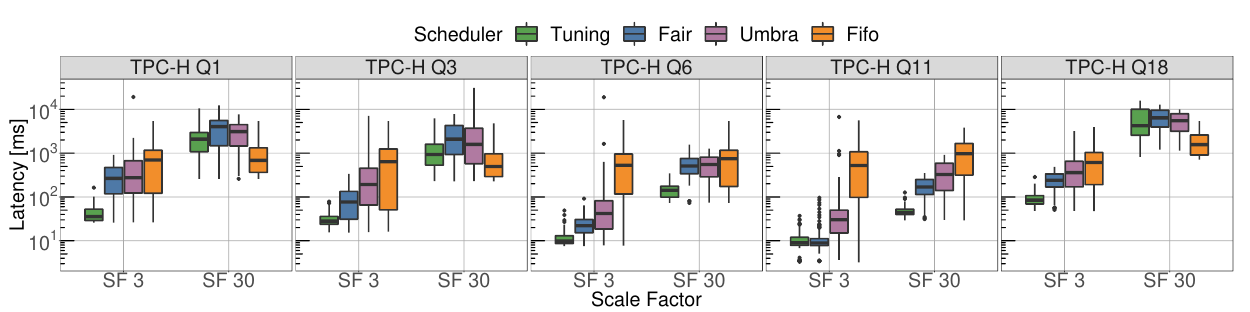
可以看到对q1和q3的sf3下的短查询都是优先处理的,并且对短查询的尾延迟有显著影响。同时还能稍微改善长查询的平均延迟和尾延迟。
5.3 Scheduling Overhead
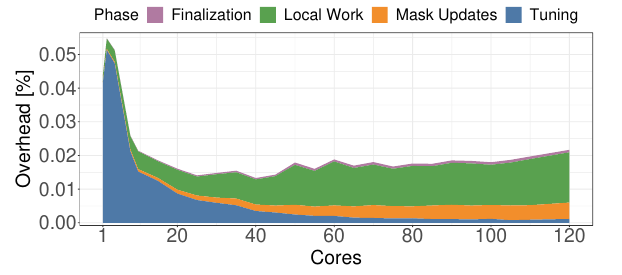
本节调查在高核心系统上的调度开销,使用Intel Xeon E7-4870 v2 CPU的四插槽机器上进行。该机器总共有60个物理核心、120个虚拟核心和1TB的内存。
如下图所示,拆分调度开销,在核心数n下同时调度个查询,然后测量不同阶段的开销直到所有查询完成。可以看到总共的调度开销是微不足道的仅占0.02%~0.05%
5.4 Comparison to Other Systems
本节评估我们的调度器与其他系统。将与postgresql、monetdb、使用原始调度器的umbra进行比较。设计一个公平的实验相对困难,因为查询延迟还与系统的执行引擎相关。为此,关闭umbra的预编译查询,在umbra和monetdb上跑20分钟,在postgresql上跑30分钟,由于postgresql和monetdb完全使用操作系统的调度,所以限制了最大并发查询数量来防止资源争用降低吞吐。
下图展示了不同系统在接近满负载时的延迟,可以看到我们的调度器始终提供最佳性能,此外也能应对最高的调度压力,每秒执行的查询比monetdb多84%,而对于postgresql这一差距则增长10倍
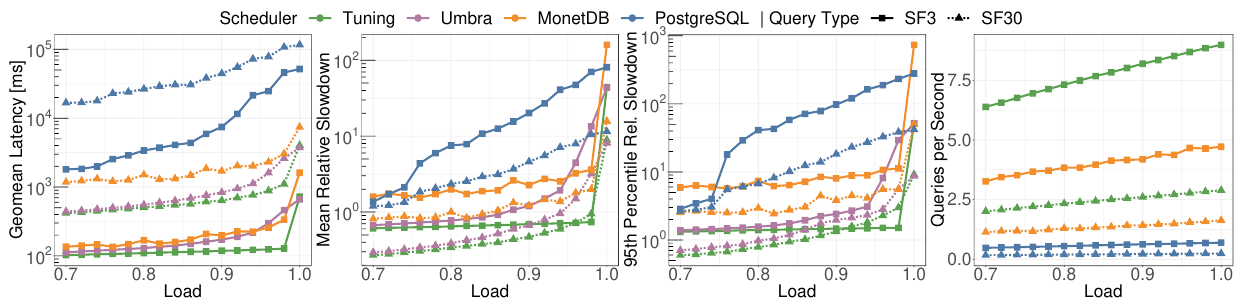
总体而言,我们已经证明我们的自调度器能够在高负载下显著超越传统系统。对于短时间运行的请求,收益尤其显著。这导致了可预测和高效的查询性能。
6 Related Work
数据库系统中的分析查询调度尚未得到广泛研究,而morsels的并行性工作为我们的贡献奠定了基础。但是其主要关注于优化numa系统上孤立请求的延迟。我们自适应小块大小的设计引入了一种原则性的方法,用于在数据库系统中改变任务粒度。这允许在整体调度行为中进行高度动态的变化。
在本文中,我们关注的是如何在单节点数据库中将细粒度工作分配到可用的CPU核心上。相比之下,大型集群中的调度则关注于在可用节点之间分配更粗粒度的任务。一个显著的例子是Spark。Kraska等人最近的工作提出使用基于强化学习的调度器来改善延迟特性。这种方法使得对活动查询的进展保证变得极其困难。我们设计的目标是在固定调度策略的约束下优化超参数,而不是试图学习一个最优的调度策略。
在更广泛的背景下,我们的调度工作属于数据库系统中工作负载管理的重要领域。这是一个广泛的领域,涉及工作负载分类、接纳控制以及内存和I/O的资源管理等主题
7 Conclusion
本文展示了如何利用基于任务的并行性来提高现代分析数据库系统的性能。我们无锁的步幅调度实现利用领域知识来改善调度决策。这对于小块驱动的数据库系统尤其具有吸引力,我们展示了如何使任务结构更加稳健。通过使我们的调度器具备自调节能力,我们使其能够为任意混合的分析工作负载做出智能的调度决策。这是通过根据跟踪的工作负载自适应地优化超参数来实现的。尽管传统系统在高负载下面临不可预测和高查询延迟的问题,但我们的自调节调度器缓解了这些问题。它为短时间运行的请求保持了接近最佳的延迟,同时显著改善了延迟尾部。