VLLM与大模型推理框架
本文最后更新于 2026年3月19日 下午
VLLM
VLLM v1 代码整体流程,代码版本v0.8.5
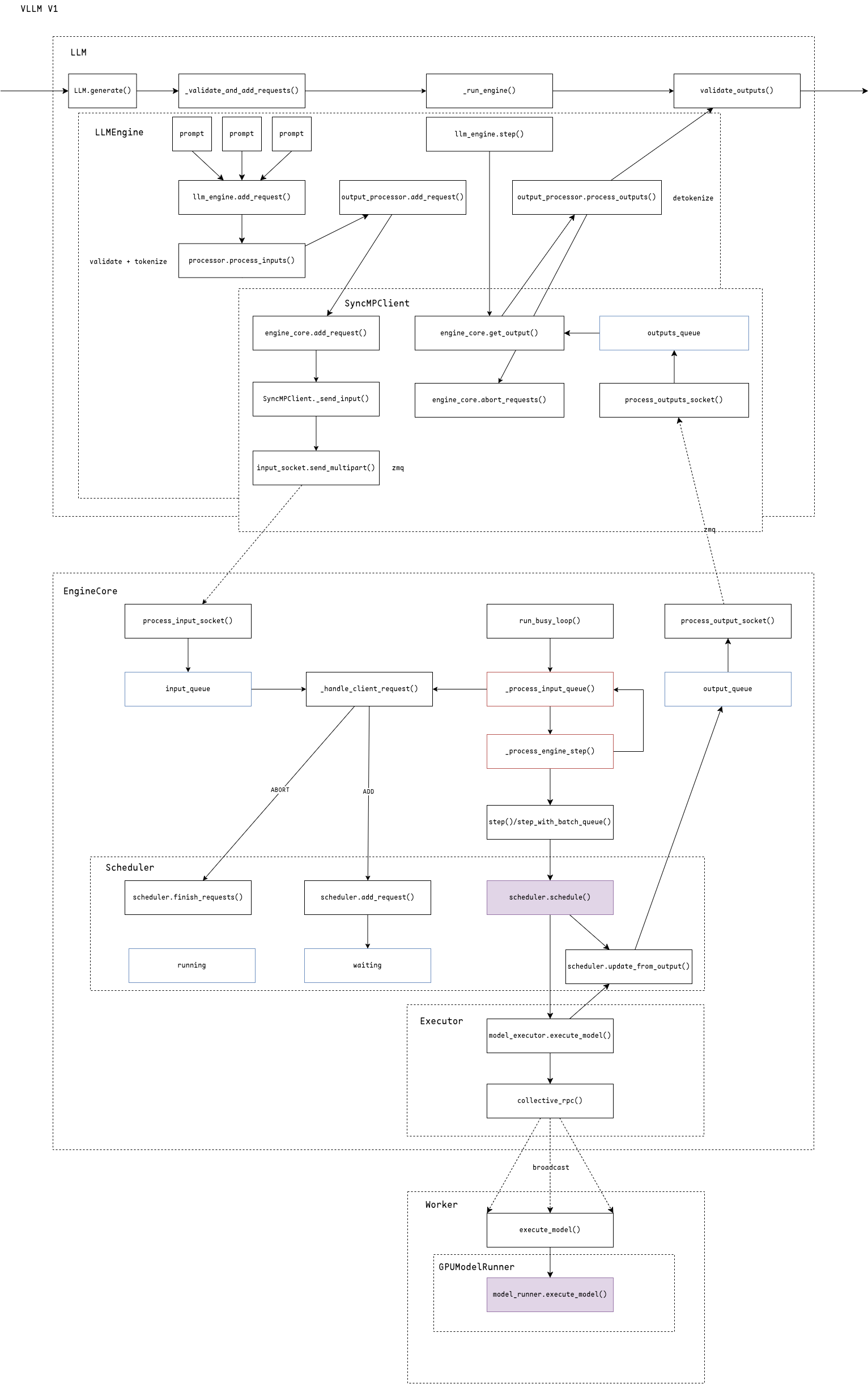
调度部分,先调度running队列,再调度waiting队列。
https://zhuanlan.zhihu.com/p/1908153627639551302
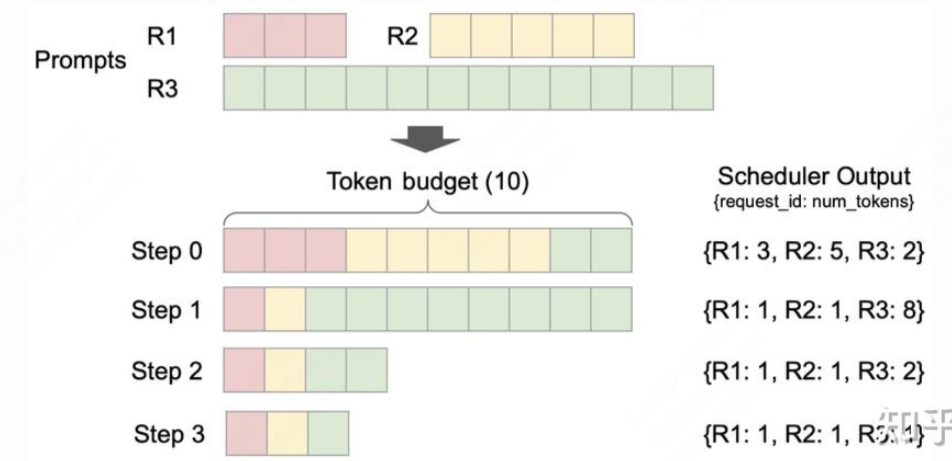
关于抢占,抢占只是释放block不再进行运算,实际等到根据LRU策略去替换block时才会真正抢占。
KV Cache
当前Q乘缓存的K,再乘缓存的V,得到第三行的Attention
调度优化
Continuous batching: https://mp.weixin.qq.com/s/Se4lzaTLNZF29BXLRjw0xw?poc_token=HC64LWijE2pWprmvhuJr1WCCkTO0yYe_G-WfBe6d
VLLM调度策略修改:https://github.com/vllm-project/vllm/issues/16969
VLLM V1调度添加优先级:https://github.com/vllm-project/vllm/issues/14002
AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference
核心在于将注意力计算和缓存管理抽象为一种查询处理流程,并通过本地查询优化器提升性能。
从总体上看,AlayaDB在LLM推理中的角色类似于传统数据库在Web应用中的作用。具体而言,LLM应用开发者只需关注应用逻辑,而AlayaDB则提供高效的长上下文管理能力,支持开发完成的LLM应用。这类似于Web开发者专注于应用逻辑,将高效的数据管理交给传统关系型数据库。
长上下文计算成本高,现有结构:
- Coupled Architecture: vllm, sglang 大量GPU内存用于存储KV缓存,以粗略的方式重用KV缓存
- KVCache Disaggregation: LMCache, MoonCake 将KV缓存拆分到外部设备,需要对引擎进行大量侵入式修改
- Retrieval-based Sparse Attention: InfLLM, Retrieval Attention 从分离的KV缓存中检索部分缓存使用,在内存消耗、推理延迟和生成质量之间进行权衡
AlayaDB将KV缓存和稀疏注意力计算与LLM推理引擎解耦,提供了:
- 用户界面
- 查询处理引擎
- 向量存储引擎
动态内积范围查询
相比于top-k,固定的k无法满足关键token数量不同的场景,使用DIPR去按比例搜寻
查询优化
- 粗粒度索引,将token向量分块并使用代表向量
- 细粒度索引,利用图索引
- 扁平索引,将keys连续存储然后顺序扫描一遍
然后使用基于规则的优化,根据prompt的上下文长度、GPU显存大小来决定使用哪种方式

CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
sparse attention类似于让Q只和部分K做计算,例如RetrievalAttention通过对KVCache做检索来做到这一点,来减少QKV点乘的开销
而CacheBlend则扩展了对KVCache的复用机制,对于相同的Token提高KVCache复用率,在第一层比对然后只重算差距大的KVCache,来减少KV计算的开销
有没有可能结合这两点
对于大规模数据处理任务,实际这种类型感觉和RAG检索很像,多了不需要上下文关联的prompt类型:
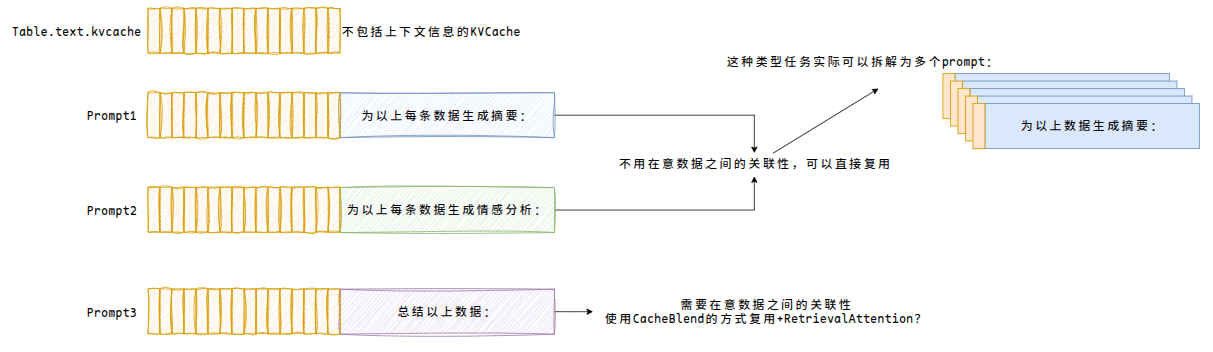
A Survey on Large Language Model Acceleration based on KV Cache Management
用于LLM加速的缓存管理策略:
- token-level:kv缓存的选择、预算分配、合并、量化、低秩分解
- model-level:架构创新、kv重用
- system-level:内存管理、调度和硬件感知
kv缓存选择:
- 静态(仅在预填充阶段进行token过滤)
- 动态(在解码阶段持续更新)
kv缓存预算分配
kv缓存合并:
- 层内合并
- 夸层合并
KV压缩
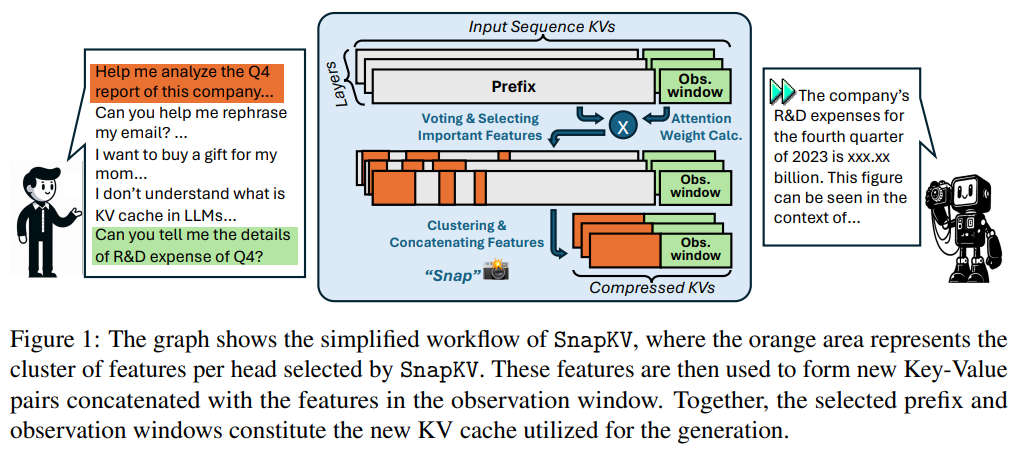
SnapKV: LLM Knows What You are Looking for Before Generation
同过观察窗口选择重要的token
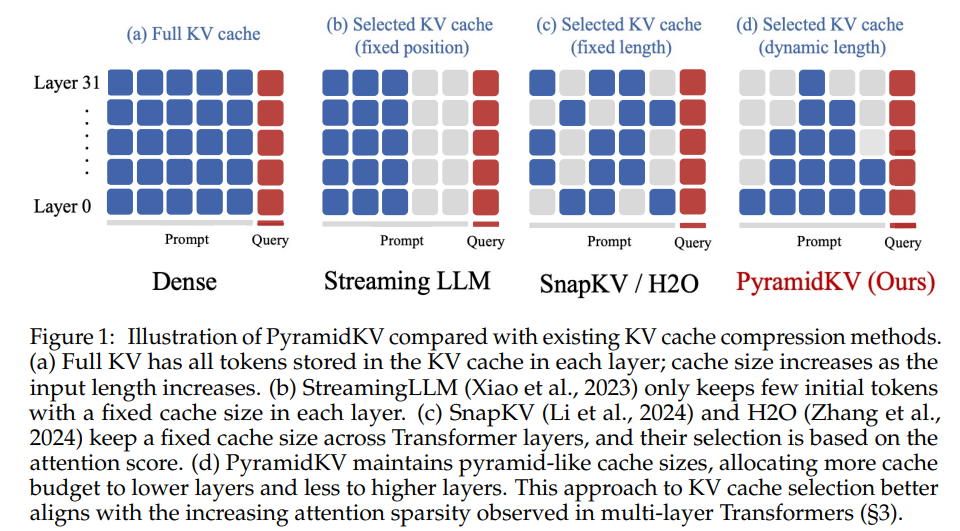
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
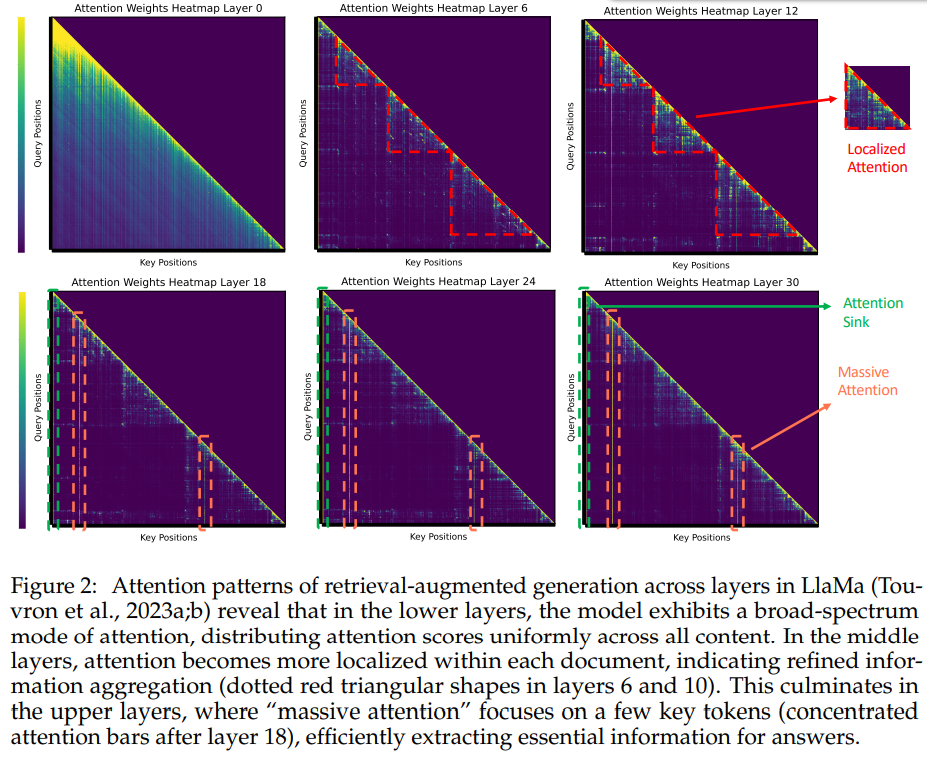
- 在模型的低层(例如第0层)中,注意力得分呈现近似均匀分布,这表明模型在较低层时从所有可用内容中全局聚合信息,而不会优先关注特定的段落。
- 当编码信息进行到中间层(6-18)时,逐渐转变为聚焦在段落内部的注意力模式 (Localized Attention)。在这个阶段,注意力主要集中在同一文档内的Token上,表明模型在单个段落内进行了段落内部的信息聚合。
- 这种趋势在上层(24-30)继续并加强,本文观察到了“Attention Sink”和“Massive Activation”现象。
为每层分配不同的缓存预算
KV复用
层间复用:
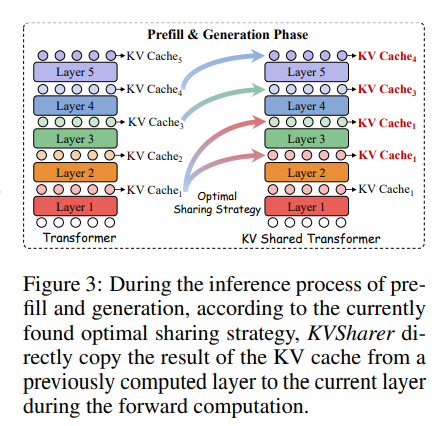
KVSHARER: EFFICIENT INFERENCE VIA LAYER-WISE DISSIMILAR KV CACHE SHARING
发现了一个违反直觉的现象:共享不相似的KV缓存能更好地保持模型性能。
首先寻找共享策略,使用校准数据集,计算每层之间的kv缓存的欧氏距离然后降序排序,依次尝试替换相应的kv缓存,确保替换过程中模型的输出保持一致,最后得到不同层之间的共享策略应用于后续的所有推理任务。
调度
- 前缀感知调度
- 抢占式和公平导向的调度
- 特定层和分层调度
nano vllm
generate -> step -> schedule -> allocate (根据block进行hash,判断prefix cache) -> model runner (init: load model -> warm up model -> allocate kv cache(算出能分配的kv cache blocks数量然后分配给模型每一层)) -> run model (prepare prefill / decode)
prefill only
hybrid prefill,线性层做chunk-by-chunk计算,减少显存占用
attention计算正常进行
使用最短作业优先策略
requst一个一个处理,因为长文本已经是compute-bound了没必要加大batch
other
多个块拼一起处理还是有优势的