VLLM测试
本文最后更新于 2026年3月19日 下午
1. 数据集
imdb影评情感分析数据集:http://ai.stanford.edu/~amaas/data/sentiment/
csv文件,格式类似如下:
| review | sentiment |
|---|---|
| text… | postive |
| text… | negtive |
2. 测试
使用模型:NousResearch/Hermes-3-Llama-3.1-8B
使用显卡:单张H800
模型最大上下文限制为(prompt tokens + output tokens):131072
KV Cache计算器:https://lmcache.ai/kv_cache_calculator.html
2.1 离线吞吐量测试
2.1.1 测试1
为使用1条prompt,格式为n个text按换行符拼接+要求:
"text1\n text2\n ... For each line of the above comments, determine whether it is a positive or negative comment. Answer only postive or negative:\n"
同时限制output token为n
2.1.2 测试2
为使用n条prompt,格式为1个text+要求:
"text1\n For the above comment, determine whether it is a positive or negative comment. Answer only postive or negative:\n"
"text2\n For the above comment, determine whether it is a positive or negative comment. Answer only postive or negative:\n"
...
同时限制每条output token为1
2.1.3 测试结果
n = 400(此时对于单条prompt来说可以认为几乎跑满了模型最大tokens限制)
测试1:
Throughput: 0.04 requests/s, 5058.22 total tokens/s, 16.80 output tokens/s
Total num prompt tokens: 120006
Total num output tokens: 400
测试2:
Throughput: 65.75 requests/s, 21299.52 total tokens/s, 65.75 output tokens/s
Total num prompt tokens: 129180
Total num output tokens: 400n = 40
测试1:
Throughput: 1.02 requests/s, 11443.23 total tokens/s, 40.65 output tokens/s
Total num prompt tokens: 11220
Total num output tokens: 40
测试2:
Throughput: 73.27 requests/s, 22262.43 total tokens/s, 73.27 output tokens/s
Total num prompt tokens: 12114
Total num output tokens: 40n = 4
测试1:
Throughput: 8.01 requests/s, 8118.47 total tokens/s, 32.03 output tokens/s
Total num prompt tokens: 1010
Total num output tokens: 4
测试2:
Throughput: 32.03 requests/s, 8648.41 total tokens/s, 32.03 output tokens/s
Total num prompt tokens: 1076
Total num output tokens: 4测试2的吞吐均大于测试1
考虑prefill阶段,测试2的batchsize更大,不考虑prefix/kv cache复用的话,长prompt的prefill(n^2)肯定是没有多个短prompt(n)快的,测试1是没有优势的
如果使用对文本的kvcache复用(可以重复交两个一样的请求,然后利用prefix机制来复用),此时在计算量上才能显现测试1的优势,因为测试1的prompt tokens数是小于测试2的(basic prompt内部的交叉注意力会多次计算)
但是考虑decode阶段,prompt越长qkv点乘计算越慢,所以测试1 decode阶段还是没有优势的
2.1.4 验证
对于测试1和测试2,同时设置一个duplicate=100,表示一个请求重复提交100次,那么后99次都会使用prefix cache进行缓存复用(同时避免basic prompt的复用,即只考虑文本块的复用),可以近似认为算出的吞吐量为完全复用时的吞吐量:
100x duplication
测试1:
Throughput: 2.47 requests/s, 297019.33 total tokens/s, 986.72 output tokens/s
Total num prompt tokens: 12000700
Total num output tokens: 40000
测试2:
Throughput: 703.70 requests/s, 229369.89 total tokens/s, 703.70 output tokens/s
Total num prompt tokens: 12998000
Total num output tokens: 40000说明如果能完全复用kv cache的话,测试1的吞吐量是更有优势的,但是decode没办法看出来,这里的output tokens计算方式是output tokens / elapsed time
如果是完全复用的话:
100x duplication
测试1:
Throughput: 2.50 requests/s, 301121.59 total tokens/s, 1000.35 output tokens/s
Total num prompt tokens: 12000600
Total num output tokens: 40000
测试2:
Throughput: 1465.77 requests/s, 476303.48 total tokens/s, 1465.77 output tokens/s
Total num prompt tokens: 12958000
Total num output tokens: 40000此时又是测试2快
2.1.5 打满batch
n = 400,文本块=4000(10prompt, 3m17s):
Throughput: 0.05 requests/s, 5847.44 total tokens/s, 19.98 output tokens/s
Total num prompt tokens: 1166840
Total num output tokens: 4000
n = 40,文本块=4000(100prompt, 53s):
Throughput: 1.78 requests/s, 20903.28 total tokens/s, 71.27 output tokens/s
Total num prompt tokens: 1169180
Total num output tokens: 4000
n = 20,文本块=4000(200prompt, 47s):
Throughput: 4.04 requests/s, 23760.10 total tokens/s, 80.83 output tokens/s
Total num prompt tokens: 1171780
Total num output tokens: 4000
n = 4,文本块=4000(1000prompt, 42s):
Throughput: 22.09 requests/s, 26438.00 total tokens/s, 88.38 output tokens/s
Total num prompt tokens: 1192580
Total num output tokens: 4000
n = 1, 文本块=4000(4000prompt, 43s):
Throughput: 85.05 requests/s, 26930.65 total tokens/s, 85.05 output tokens/s
Total num prompt tokens: 1262580
Total num output tokens: 4000验证是否打满:
n = 40,文本块=4000(100prompt, 53s):
Throughput: 1.78 requests/s, 20903.28 total tokens/s, 71.27 output tokens/s
Total num prompt tokens: 1169180
Total num output tokens: 4000
n = 40,文本块=40000(1000prompt, 9m12s):
Throughput: 1.74 requests/s, 20570.07 total tokens/s, 69.73 output tokens/s
Total num prompt tokens: 11760476
Total num output tokens: 400002.1.6 profiling
// profiling
- GPU KV cache size: 416304 tokens
- max_num_batched_tokens=16384
// 显存占用
- 显存占用监控只能在vllm内部实现,v1还没有实现log部分,v0已实现
- 显存占用不是瓶颈,计算是瓶颈:
以v0引擎为例:
修改max-num-batched-tokens参数来提高Batch数量
max_num_batched_tokens = 10000
n = 4,文本块=4000(1000prompt):
INFO 07-14 14:38:01 [llm_engine.py:437] init engine (profile, create kv cache, warmup model) took 18.80 seconds
INFO 07-14 14:38:07 [metrics.py:486] Avg prompt throughput: 15135.6 tokens/s, Avg generation throughput: 40.4 tokens/s, Running: 33 req
s, Swapped: 0 reqs, Pending: 925 reqs, GPU KV cache usage: 9.2%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:12 [metrics.py:486] Avg prompt throughput: 25464.4 tokens/s, Avg generation throughput: 81.2 tokens/s, Running: 33 req
s, Swapped: 0 reqs, Pending: 823 reqs, GPU KV cache usage: 9.4%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:17 [metrics.py:486] Avg prompt throughput: 25478.4 tokens/s, Avg generation throughput: 89.9 tokens/s, Running: 39 req
s, Swapped: 0 reqs, Pending: 704 reqs, GPU KV cache usage: 9.7%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:22 [metrics.py:486] Avg prompt throughput: 25387.7 tokens/s, Avg generation throughput: 90.7 tokens/s, Running: 31 req
s, Swapped: 0 reqs, Pending: 593 reqs, GPU KV cache usage: 9.6%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:27 [metrics.py:486] Avg prompt throughput: 25379.3 tokens/s, Avg generation throughput: 85.2 tokens/s, Running: 33 req
s, Swapped: 0 reqs, Pending: 484 reqs, GPU KV cache usage: 9.5%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:32 [metrics.py:486] Avg prompt throughput: 25350.5 tokens/s, Avg generation throughput: 84.5 tokens/s, Running: 32 req
s, Swapped: 0 reqs, Pending: 376 reqs, GPU KV cache usage: 9.2%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:37 [metrics.py:486] Avg prompt throughput: 25307.8 tokens/s, Avg generation throughput: 82.0 tokens/s, Running: 31 req
s, Swapped: 0 reqs, Pending: 272 reqs, GPU KV cache usage: 9.4%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:42 [metrics.py:486] Avg prompt throughput: 25275.8 tokens/s, Avg generation throughput: 81.5 tokens/s, Running: 35 req
s, Swapped: 0 reqs, Pending: 165 reqs, GPU KV cache usage: 9.4%, CPU KV cache usage: 0.0%.
INFO 07-14 14:38:48 [metrics.py:486] Avg prompt throughput: 25202.6 tokens/s, Avg generation throughput: 85.2 tokens/s, Running: 34 req
s, Swapped: 0 reqs, Pending: 56 reqs, GPU KV cache usage: 9.3%, CPU KV cache usage: 0.0%.
Throughput: 20.32 requests/s, 24316.25 total tokens/s, 81.29 output tokens/s
Total num prompt tokens: 1192580
Total num output tokens: 4000
max_num_batched_tokens = 80000
n = 4,文本块=4000(1000prompt):
INFO 07-14 15:08:55 [metrics.py:486] Avg prompt throughput: 15254.3 tokens/s, Avg generation throughput: 12.6 tokens/s, Running: 129 re
qs, Swapped: 0 reqs, Pending: 871 reqs, GPU KV cache usage: 41.1%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:01 [metrics.py:486] Avg prompt throughput: 26310.4 tokens/s, Avg generation throughput: 53.3 tokens/s, Running: 267 re
qs, Swapped: 0 reqs, Pending: 733 reqs, GPU KV cache usage: 82.3%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:07 [metrics.py:486] Avg prompt throughput: 26104.8 tokens/s, Avg generation throughput: 95.6 tokens/s, Running: 267 re
qs, Swapped: 0 reqs, Pending: 605 reqs, GPU KV cache usage: 78.6%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:13 [metrics.py:486] Avg prompt throughput: 25025.7 tokens/s, Avg generation throughput: 84.4 tokens/s, Running: 263 re
qs, Swapped: 0 reqs, Pending: 471 reqs, GPU KV cache usage: 78.1%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:19 [metrics.py:486] Avg prompt throughput: 25783.0 tokens/s, Avg generation throughput: 85.4 tokens/s, Running: 255 re
qs, Swapped: 0 reqs, Pending: 350 reqs, GPU KV cache usage: 78.5%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:25 [metrics.py:486] Avg prompt throughput: 25851.4 tokens/s, Avg generation throughput: 89.0 tokens/s, Running: 246 re
qs, Swapped: 0 reqs, Pending: 226 reqs, GPU KV cache usage: 78.4%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:31 [metrics.py:486] Avg prompt throughput: 25812.8 tokens/s, Avg generation throughput: 80.7 tokens/s, Running: 260 re
qs, Swapped: 0 reqs, Pending: 90 reqs, GPU KV cache usage: 81.4%, CPU KV cache usage: 0.0%.
INFO 07-14 15:09:37 [metrics.py:486] Avg prompt throughput: 25849.6 tokens/s, Avg generation throughput: 89.8 tokens/s, Running: 226 re
qs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 68.3%, CPU KV cache usage: 0.0%.
Throughput: 20.64 requests/s, 24698.61 total tokens/s, 82.56 output tokens/s
Total num prompt tokens: 1192580
Total num output tokens: 4000
max_num_batched_tokens = 160000
n = 4,文本块=4000(1000prompt):
INFO 07-14 15:15:48 [metrics.py:486] Avg prompt throughput: 18817.5 tokens/s, Avg generation throughput: 15.1 tokens/s, Running: 266 re
qs, Swapped: 0 reqs, Pending: 734 reqs, GPU KV cache usage: 98.9%, CPU KV cache usage: 0.0%.
INFO 07-14 15:15:54 [metrics.py:486] Avg prompt throughput: 25767.2 tokens/s, Avg generation throughput: 43.1 tokens/s, Running: 266 re
qs, Swapped: 0 reqs, Pending: 734 reqs, GPU KV cache usage: 99.0%, CPU KV cache usage: 0.0%.
INFO 07-14 15:16:00 [metrics.py:486] Avg prompt throughput: 24324.2 tokens/s, Avg generation throughput: 124.5 tokens/s, Running: 276 r
eqs, Swapped: 0 reqs, Pending: 458 reqs, GPU KV cache usage: 98.9%, CPU KV cache usage: 0.0%.
INFO 07-14 15:16:07 [metrics.py:486] Avg prompt throughput: 25612.9 tokens/s, Avg generation throughput: 44.1 tokens/s, Running: 276 re
qs, Swapped: 0 reqs, Pending: 458 reqs, GPU KV cache usage: 99.0%, CPU KV cache usage: 0.0%.
INFO 07-14 15:16:13 [metrics.py:486] Avg prompt throughput: 23555.6 tokens/s, Avg generation throughput: 121.8 tokens/s, Running: 257 r
eqs, Swapped: 0 reqs, Pending: 201 reqs, GPU KV cache usage: 98.0%, CPU KV cache usage: 0.0%.
INFO 07-14 15:16:20 [metrics.py:486] Avg prompt throughput: 25548.9 tokens/s, Avg generation throughput: 41.5 tokens/s, Running: 258 re
qs, Swapped: 0 reqs, Pending: 200 reqs, GPU KV cache usage: 98.9%, CPU KV cache usage: 0.0%.
INFO 07-14 15:16:26 [metrics.py:486] Avg prompt throughput: 24392.9 tokens/s, Avg generation throughput: 118.3 tokens/s, Running: 200 r
eqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 73.3%, CPU KV cache usage: 0.0%.
Throughput: 19.98 requests/s, 23911.86 total tokens/s, 79.93 output tokens/s
Total num prompt tokens: 1192580
Total num output tokens: 4000可见尽管提高batchsize和kvcache的显存占用,吞吐量也没有较大变化,说明计算已达瓶颈
- 显存占用可视化:
https://huggingface.co/blog/train_memory
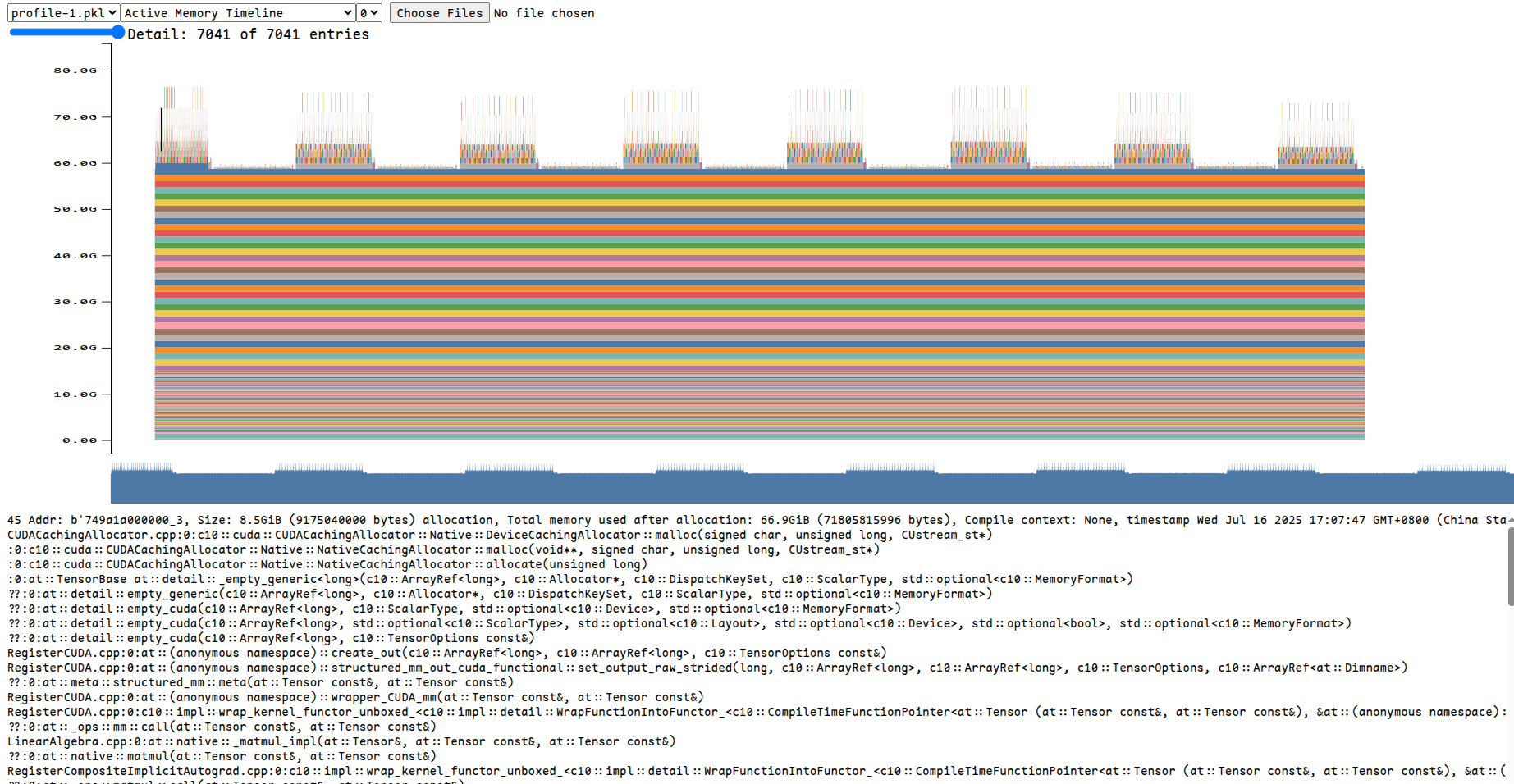
- 其他profiling(函数级别的profiling):
pytorch profile、nvidia nsight system
- 关于计算复杂度:
没有考虑隐藏层维度d和线性层变换复杂度
(llama3.1参数计算分析:https://zhuanlan.zhihu.com/p/25434610561):
当N较小时,计算复杂度以线性层变换为主导,所以差距不大
文本块长度:L1
Basic prompt长度:L2
一条Prompt包含的文本块数量:x
总的文本块数量:n
那么一共有条prompt
对于一条prompt的推理,比较严谨的一种时间复杂度为(N为prompt长度,d为特征维度,、为常量系数,为潜在的可能和x有关的时间开销):
总共的时间复杂度:
只需考虑变量x,本质是一种形如的函数
根据前面测试的样本拟合得到的函数:
红色线条为拟合函数,蓝色线条为测得的样本,横坐标为x(一个prompt所包含的文本块数量),纵坐标为时间(秒)

为使拟合成立,需要满足以下条件:
令
解得
说明是存在一种可行解的,即结果上存在x=1和x=4两者吞吐差不多的可能,并且在x增大时所呈现的趋势也符合分析得到的函数,而之前分析得到的3.6倍差距并没有考虑到实际的常量系数关系
// sparse attention model
使用模型:neuralmagic/Sparse-Llama-3.1-8B-2of4
n = 400,文本块=4000(10prompt, 3m18s):
Throughput: 0.05 requests/s, 5841.18 total tokens/s, 19.96 output tokens/s
Total num prompt tokens: 1166840
Total num output tokens: 4000
n = 20,文本块=4000(200prompt, 46s)
Throughput: 4.13 requests/s, 24274.25 total tokens/s, 82.58 output tokens/s
Total num prompt tokens: 1171780
Total num output tokens: 4000
n = 4,文本块=4000(1000prompt, 41s):
Throughput: 22.74 requests/s, 27214.20 total tokens/s, 90.97 output tokens/s
Total num prompt tokens: 1192580
Total num output tokens: 4000
n = 1, 文本块=4000(4000prompt, 42s):
Throughput: 87.79 requests/s, 27973.23 total tokens/s, 87.79 output tokens/s
Total num prompt tokens: 1270580
Total num output tokens: 40002.2 在线吞吐量测试
n = 400
测试1:
============ Serving Benchmark Result ============
Successful requests: 1
Benchmark duration (s): 7.29
Total input tokens: 120006
Total generated tokens: 400
Request throughput (req/s): 0.14
Output token throughput (tok/s): 54.89
Total Token throughput (tok/s): 16524.00
---------------Time to First Token----------------
Mean TTFT (ms): 293.37
Median TTFT (ms): 293.37
P99 TTFT (ms): 293.37
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 17.52
Median TPOT (ms): 17.52
P99 TPOT (ms): 17.52
---------------Inter-token Latency----------------
Mean ITL (ms): 17.52
Median ITL (ms): 17.40
P99 ITL (ms): 19.57
==================================================
测试2:
============ Serving Benchmark Result ============
Successful requests: 400
Benchmark duration (s): 4.84
Total input tokens: 129180
Total generated tokens: 400
Request throughput (req/s): 82.71
Output token throughput (tok/s): 82.71
Total Token throughput (tok/s): 26794.76
---------------Time to First Token----------------
Mean TTFT (ms): 2706.23
Median TTFT (ms): 2815.29
P99 TTFT (ms): 4828.05
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 0.00
Median TPOT (ms): 0.00
P99 TPOT (ms): 0.00
---------------Inter-token Latency----------------
Mean ITL (ms): 0.00
Median ITL (ms): 0.00
P99 ITL (ms): 0.00
==================================================