以nano-vllm和qwen3为例详解大模型推理过程
本文最后更新于 2026年3月19日 下午
源码仅1200行纯python,十分推荐观看:
https://github.com/GeeeekExplorer/nano-vllm
另外关于vllm的逻辑:
https://www.aleksagordic.com/blog/vllm
1. qwen3模型结构和推理过程(prefill)
1.1 分词器
分词器的作用是将文本(str)编码为整数序列(list[int])
需要预先训练分词器来得到词汇表(vocab),即文本到token id的映射,而词汇表大小是固定的,对于qwen3,vocab_size=151936
分词器可以是单词级(词汇表过大),也可以是字符级(会导致编码的序列过大)
现在的主流大模型均使用BPE分词器,结合了两种方式的优点,具体而言,其将文本根据utf-8编码转换为字节序,然后统计所有字节对的频率,不断将频率最高的字节对合并构成新的词汇
这样相当于把常见的单词合并为一个词汇,不常见的还是按照字符级处理,防止词汇表过大
分词器在线示例:https://tiktokenizer.vercel.app/
例如:
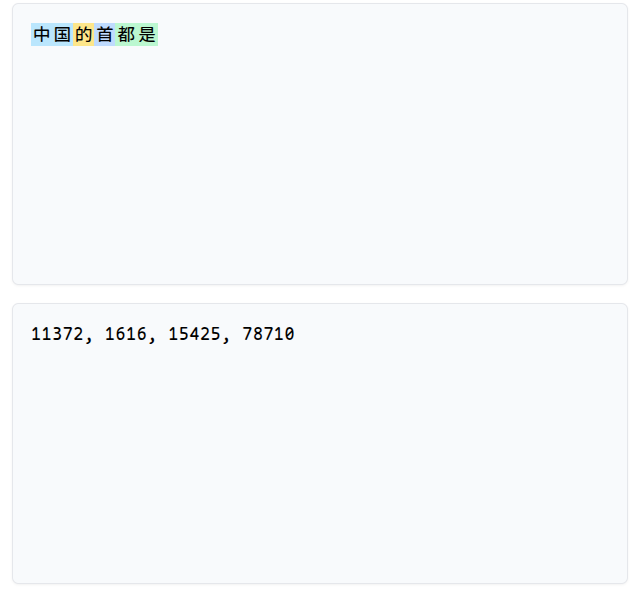
1.1.1 train bpe
分词器需要训练数据预训练出词汇表:
首先初始化词汇表0-255,此时根据utf-8编码就可以编码所有文本,但是这样编码出的文本过长,所以进行字节对合并操作
例如给定文本"hello llm",首先根据如下正则表达式分割为单词
r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
["hello", " llm"],得到字节对[b"he", b"el", b"ll", b"lo", b" l", b"ll", b"lm"],此时b"ll"频率最大,将其作为新的词汇加入词汇表"ll" -> 256,同时维护合并历史merges=[b"ll"]
此时"ll"被看作整体,得到新的字节对[b"he", b"ell", b"llo", b" ll", b"llm"],然后再根据频率合并,依次类推,得到扩展的词汇表和合并历史
1.1.2 bpe encode
对于给定的文本,还是分词为字节序,如何根据合并历史合并为不同的词汇,最后根据词汇表映射为token id
1.1.3 bpe decode
对于给定的token id,根据词汇表直接转换为字节序然后utf-8解码为文本
1.2 模型结构
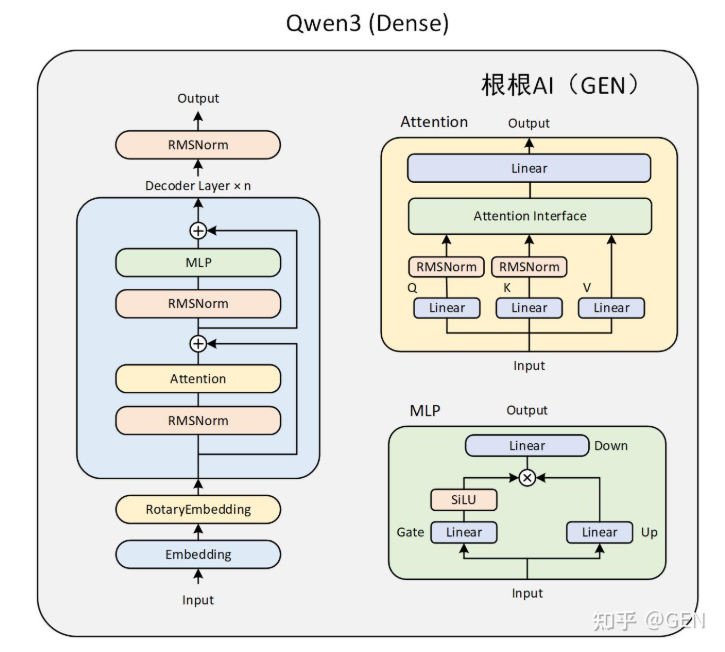
经过分词器后,输入是一个Tensor[batch_size, seq_len]的张量,其中batch_size=n即n条prompt,值为token id
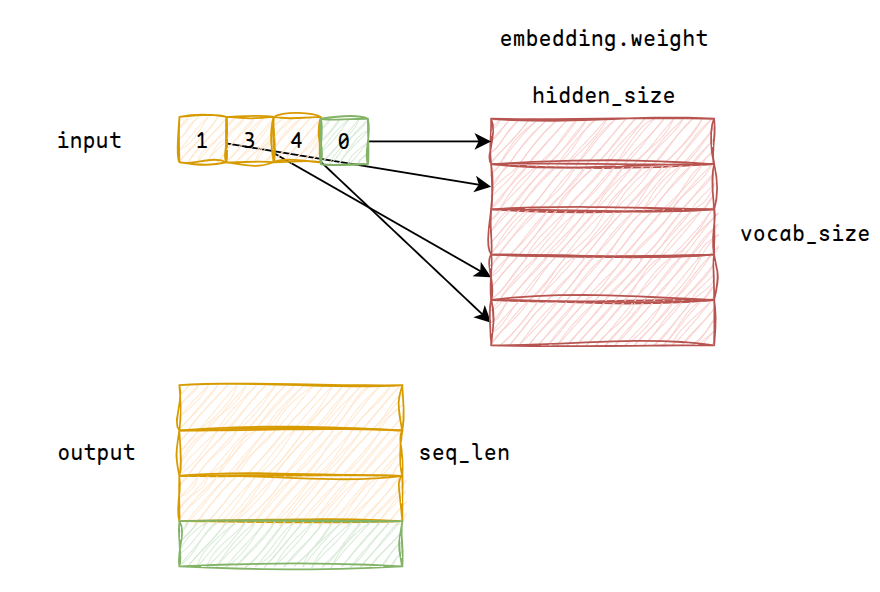
1.2.1 embedding
首先是embedding模块,可训练参数为Tensor[vocab_size, hidden_size],根据token_id索引,将input序列转换为Tensor[batch_size, seq_len, hidden_size]
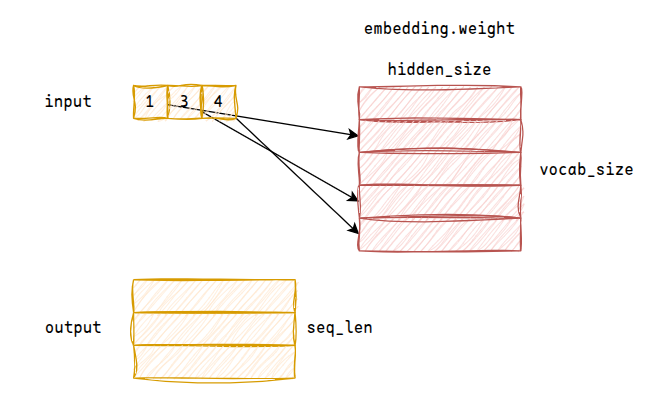
对于超参数hidden_size,一般又叫作d_model
embedding weight包含了文本的语义信息,例如“男人”、“女人”的向量距离更近
1.2.2 decoder layer
然后是n层decoder layer,其中包含三个模块
RMSNorm
归一化模块,相较于LayerNorm,目前主流大模型都使用了RMSNorm,因其计算量更小并且效果不差
具体公式为
其中是可训练参数Tensor[hidden_size]
输出维度仍然是Tensor[batch_size, seq_len, hidden_size]

这个归一化层哪里都可以放,有的模型放在attention计算前面(pre-norm)有的放在后面(post-norm),qwen3甚至在每个q和k后面也放了一层,效果不尽相同
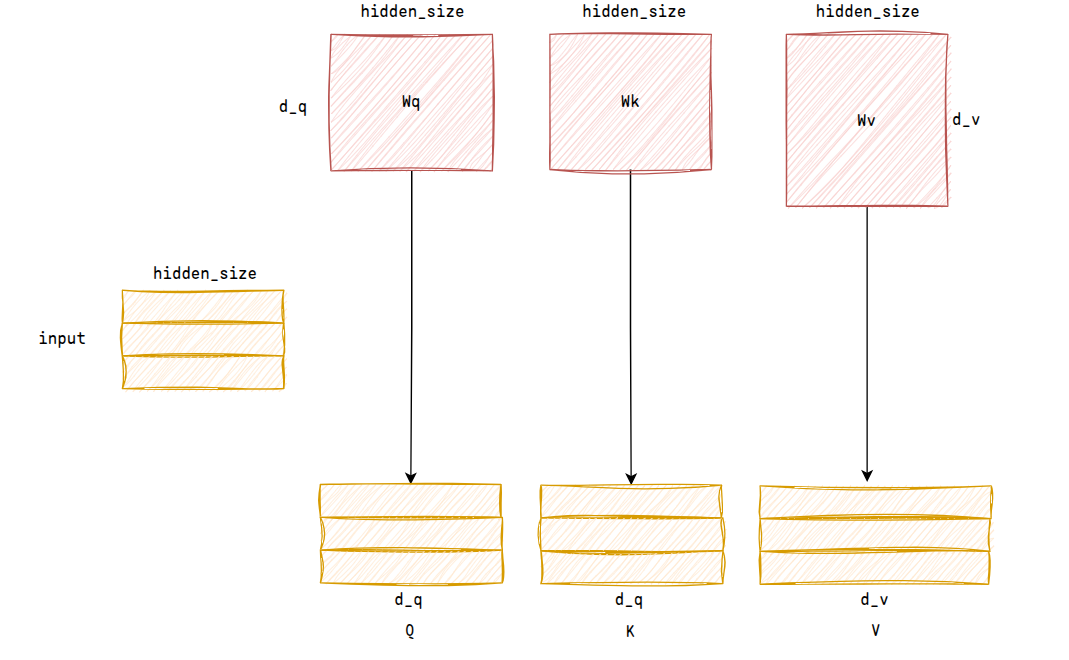
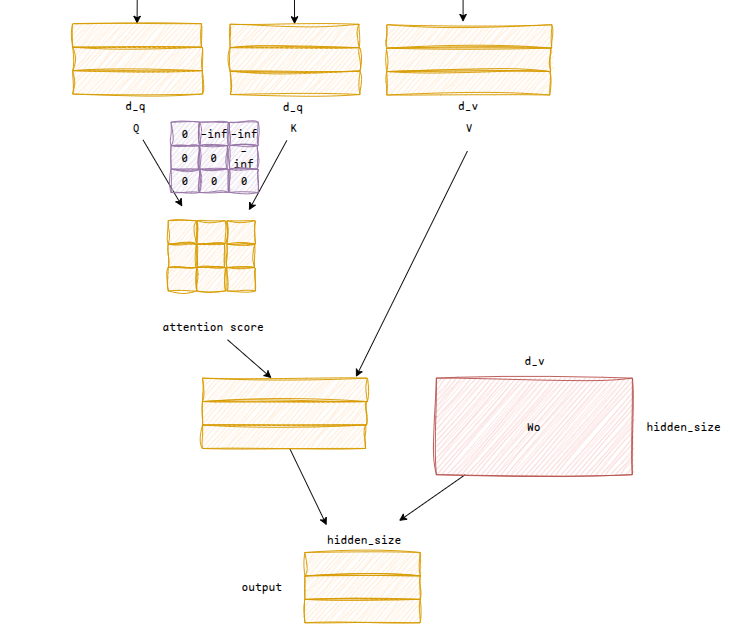
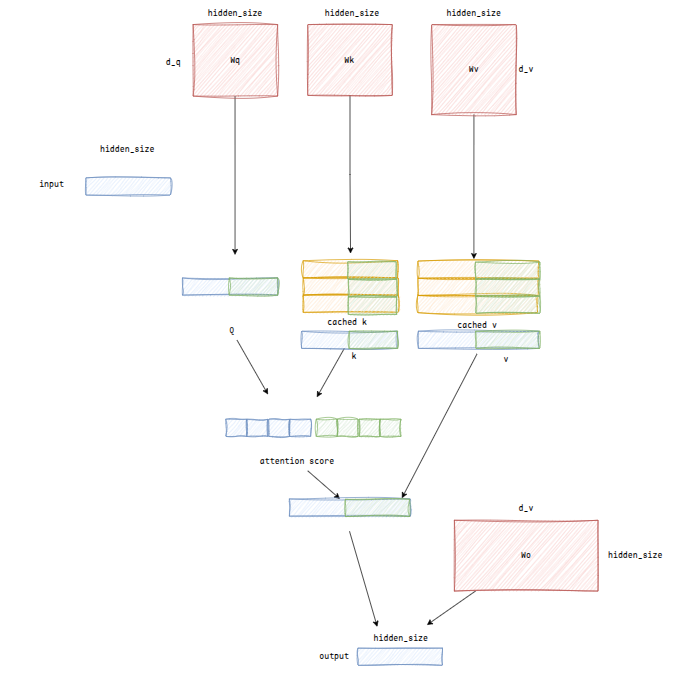
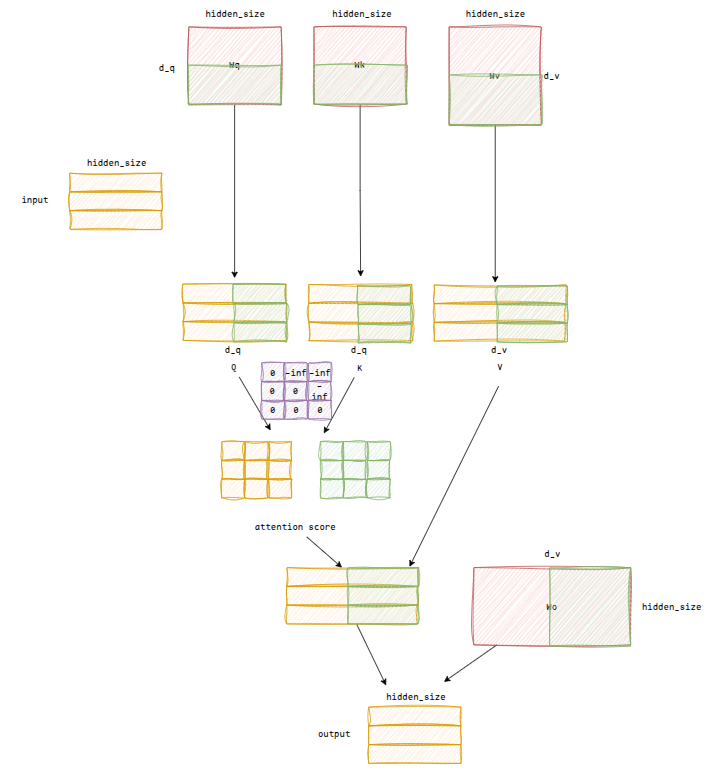
Attention
attention模块中,有三个q、k、v权重可训练参数Tensor[hidden_size, d_q], Tensor[hidden_size, d_q], Tensor[hidden_size, d_v]
输入经过线性变换后得到q、k、v矩阵Tensor[batch_size, seq_len, d_q], Tensor[batch_size, seq_len, d_q], Tensor[batch_size, seq_len, d_v]
注意力得分计算公式为:,得到张量Tensor[batch_size, seq_len, seq_len],其中softmax计算公式为,一般来说如果过大会导致指数爆炸,所以减去了中最大值,这样得到的值相当于一个伪概率分布(指数函数将值限制在正象限,然后进行归一化处理限制在[0-1],并且和为1),值越大的地方表示这个token和之前某个token关联度越高
除此之外,还要加入causal mask,来限制未来信息泄露,注意causal mask必须在softmax之前加,不然结果的和不为1
然后和V做矩阵乘法,得到Tensor[batch_size, seq_len, d_v],一般而言还会有一个output_proj可训练参数,用于将维度变换到,输出为Tensor[batch_size, seq_len, hidden_size]
ROPE
注意目前没有考虑到位置编码,其作用是让大模型捕获到位置信息,即相同单词在不同位置的含义是不一样的,传统做法是使用绝对位置编码,即在embedding层后加上绝对位置编码信息,但是之后的主流做法是使用旋转位置编码
关于旋转位置编码原理推荐看:https://zhuanlan.zhihu.com/p/662790439
具体而言需要一个旋转矩阵
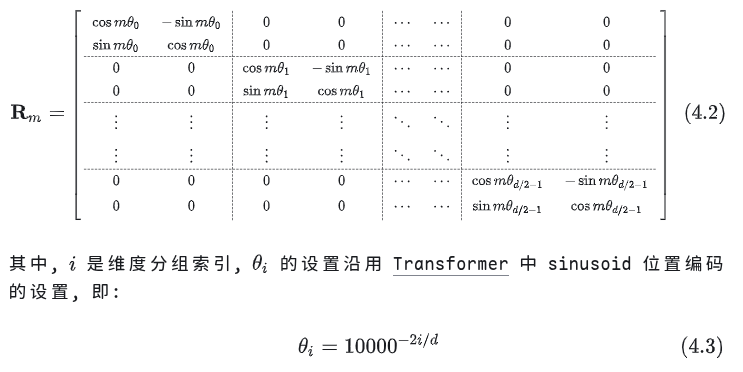
注意这里是两两分组的,表示对向量进行位置m的旋转,将旋转矩阵分别应用到Q和K上面,这样在计算QK时就能表示相对位置信息,比如第i个token的q矩阵和第j个token的k矩阵:
另外由于是稀疏矩阵,并且旋转矩阵是固定的,所以一般都会对旋转矩阵进行缓存
还是以之前的Q为例,计算过程如下
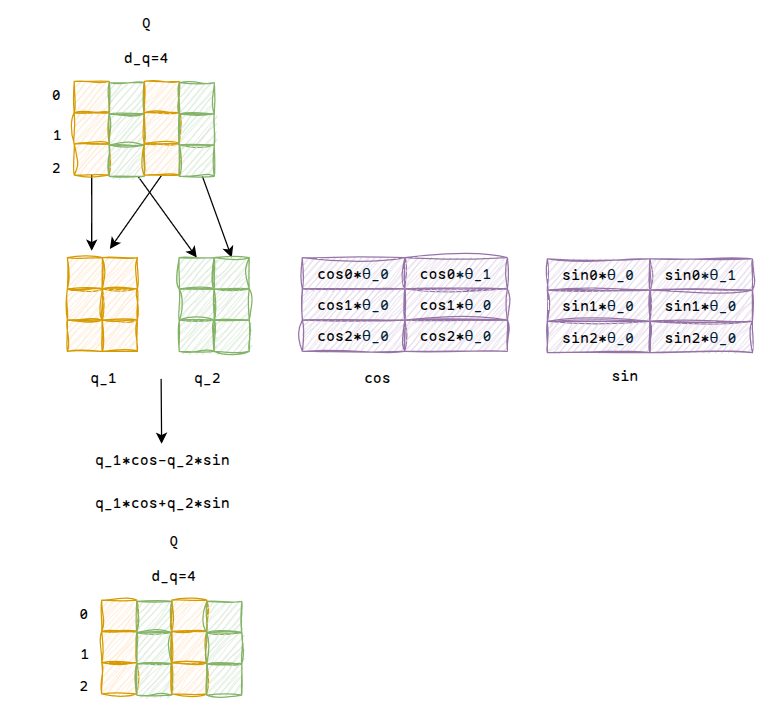
注意这里有max_positions的限制,对于超过的部分要考虑旋转位置编码的外推性,感兴趣可以看看,不再赘述
multi-head attn
之前介绍的attn计算是单头的,实际会计算多头,实际就是对d_q维度拆分为num_heads*head_dim,例如如果是两个头,那么之前的计算过程变为:
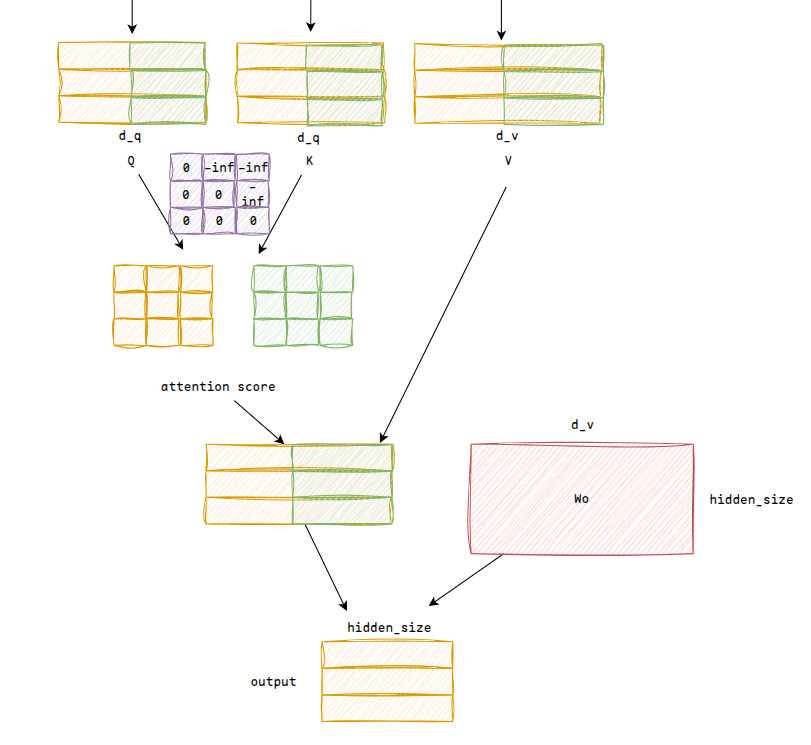
实际就是多算了个attention score,另外注意换成多头的话,ROPE会单独上给每个头
另外qwen3实际是GQA的结构,具体后续再说
Residual
attention后是一个残差连接,即x=x+attn(rms(x)),减轻深度网络训练的权重退化问题
MLP
mlp即各种线性层的变换了,对于qwen3来说,计算为:
def SiLU(x):
x = x / (1+e^{-x})
x = (SiLU(xW_gate)+xW_up )x_down1.2.3 output
历经n层decoder layer之后,再进行最后一层的RMSNorm归一化,得到最总的结果,而我们只需关注最后一行的结果,此时进行一次线性变换,将hidden_size扩展到vocab_size
sampling
采样时有采样温度t,如果t=0,则直接选择值最大的token,否则做缩放softmax然后添加噪声并按概率采样

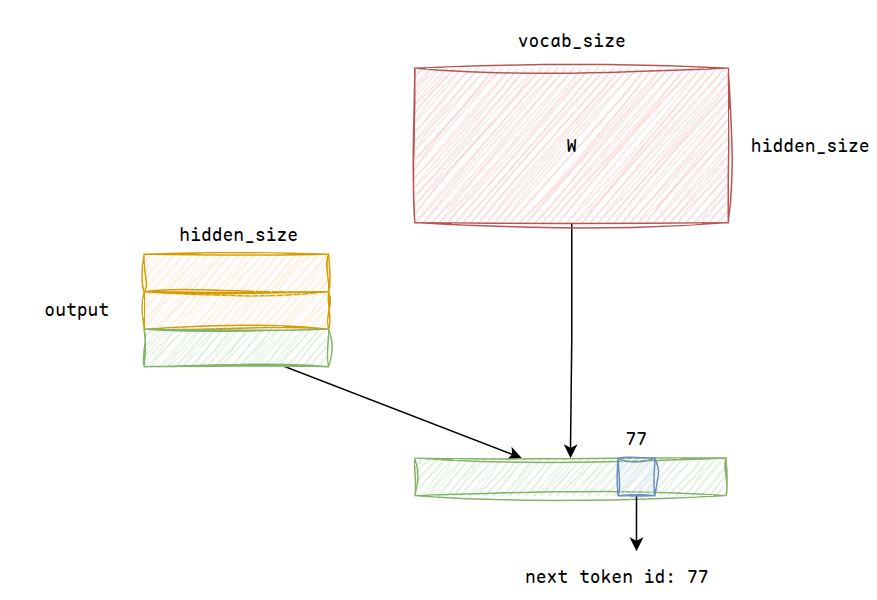
1.2.4 autoregressive
得到的next token id将进行新一轮的自回归循环:
2. nano-vllm推理服务和优化(decode)
2.1 参数分析
一个token需要的kv cache大小:
2 * decode_layers * num_kv_heads * head_size * bytesAttention计算量,计算量与头数无关:
hidden_size = num_q_heads * head_size
FLOPs = 6 * seq_len * hidden_size * hidden_size + (q k v)
2 * seq_len * seq_len * hidden_size + (qk)
3 * seq_len * seq_len + (softmax)
2 * seq_len * seq_len * hidden_size + (qkv)
2 * seq_len * hidden_size * hidden_size (qkvo)
= 8ND^2 + 4N^2D + 3N^2MLP计算量:
FLOPs = 2 * seq_len * hidden_size * d_ff +
2 * seq_len * hidden_size * d_ff +
2 * seq_len * d_ff * hidden_size +
4 * seq_len * d_ff
= 6NDD_ff + 4ND_ffROPE计算量:
FLOPs = 4 * seq_len * hidden_size
= 4NDRMSNorm计算量:
FLOPs = 3ND2.2 KV Cache
观察之前介绍的结构,由于最终结果我们只需要关注最后一行,所以实际上我们可以把中途计算的kv矩阵缓存起来,然后在decode阶段,只需要输入一个token即可(seq_len=1,关注蓝色部分)
其他模块的输入也都只要一行token输入即可,唯独attention模块中需要缓存k和v
2.3 GQA
由于decoder layer有多层,所以需要的kv缓存也较多,为了减少kv缓存,又提出了GQA、MQA
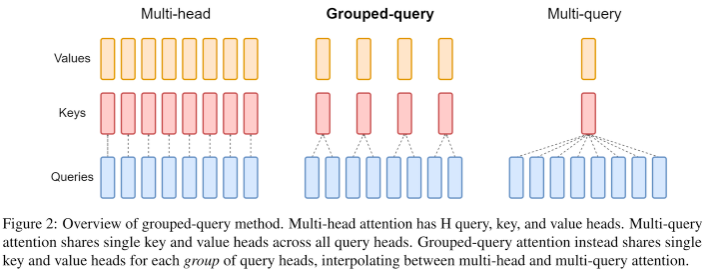
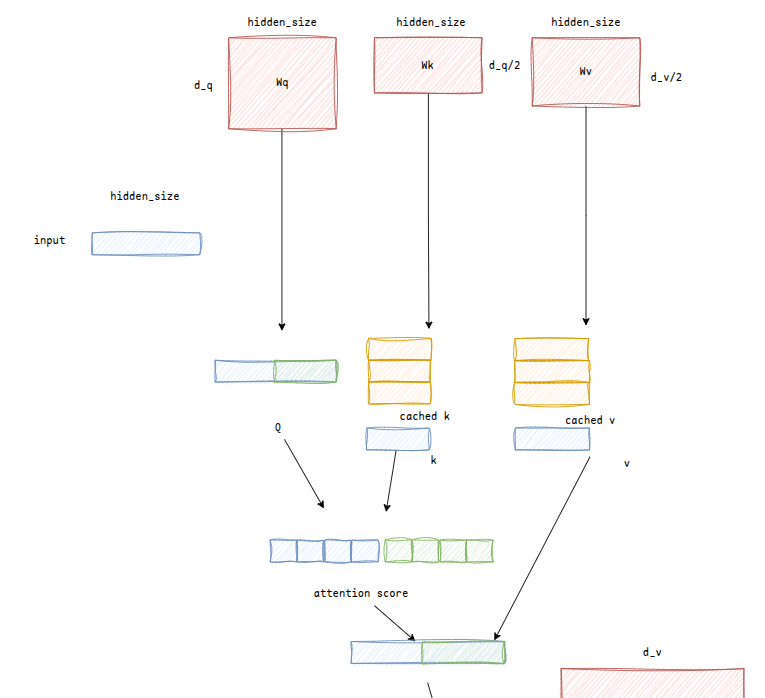
qwen3使用了GQA,将多个头的q分为一组共用k和v,减少缓存量的同时获得了和MHA相当的性能
如图将两个Q分为一组,注意参数wk和wv的维度也得到了减少:
2.4 Paged Attention
kv缓存减少了,但是实际存在kv cache怎么放的问题,如果只靠GPU分配kv缓存时会造成很多内部/外部空隙,所以vllm利用类似于操作系统的虚拟页表方式,进行kv cache的分块管理
首先会在GPU显存中开辟一个很大范围的kv cache张量Tensor[2, num_hidden_layers, num_kvcache_blocks, block_size, num_kv_heads, head_dim]
前两个维度会分配给每一层layer的k_cache/v_cache中,num_kvcache_blocks是根据显存算出来的最大块大小,block_size表示一个块里面放几个token的kv cache,num_kv_heads则表示不同头的kv cache,head_dim即最终存的kv cache
例如对于一个500tokens的输入,假设block_size=256,那么需要分配两个空闲物理块比如分配到了3、4,此时进行prefill,算出k和v矩阵后,就根据3和4存到对应的block中
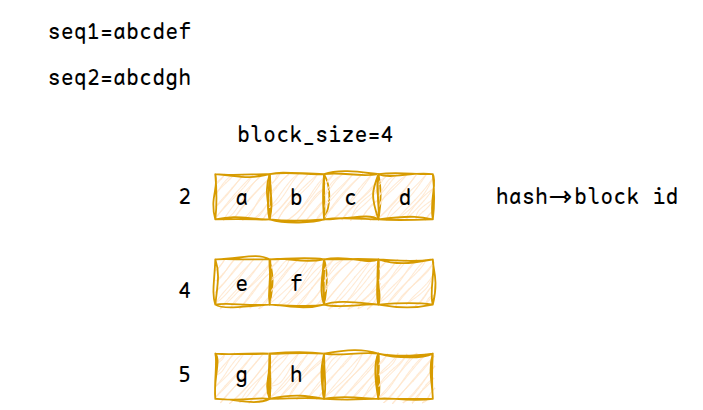
prefix cache
当多个输入的prefix prompt相同时,可以进行prefix cache,这个是根据block hash计算的
例如下图,此时block2的ref为2,因为同时被seq1和seq2所使用,这个时候seq2的prefill只需要输入gh就行了,因为abcd的kv都已经算过了
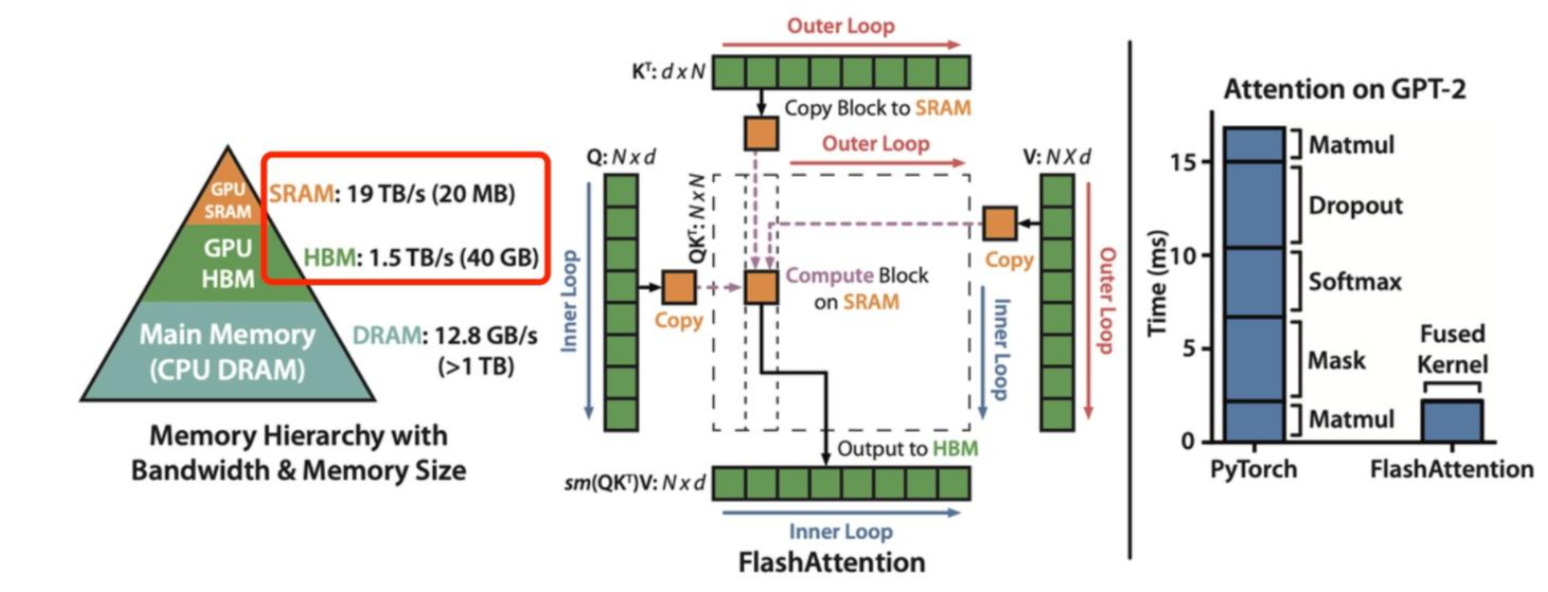
2.5 Flash Attention
解决了kv cache怎么放的问题,还有kv cache怎么读的问题,因为decode阶段输入仅一个token,基本都是memory-bound的,为此提出flash attention优化访存
GPU结构
注意GPU内部结构,一个cuda kernel包含多个block,每个block内部有256个线程,一个block运行在一个SM上,调度以warp为单元进行
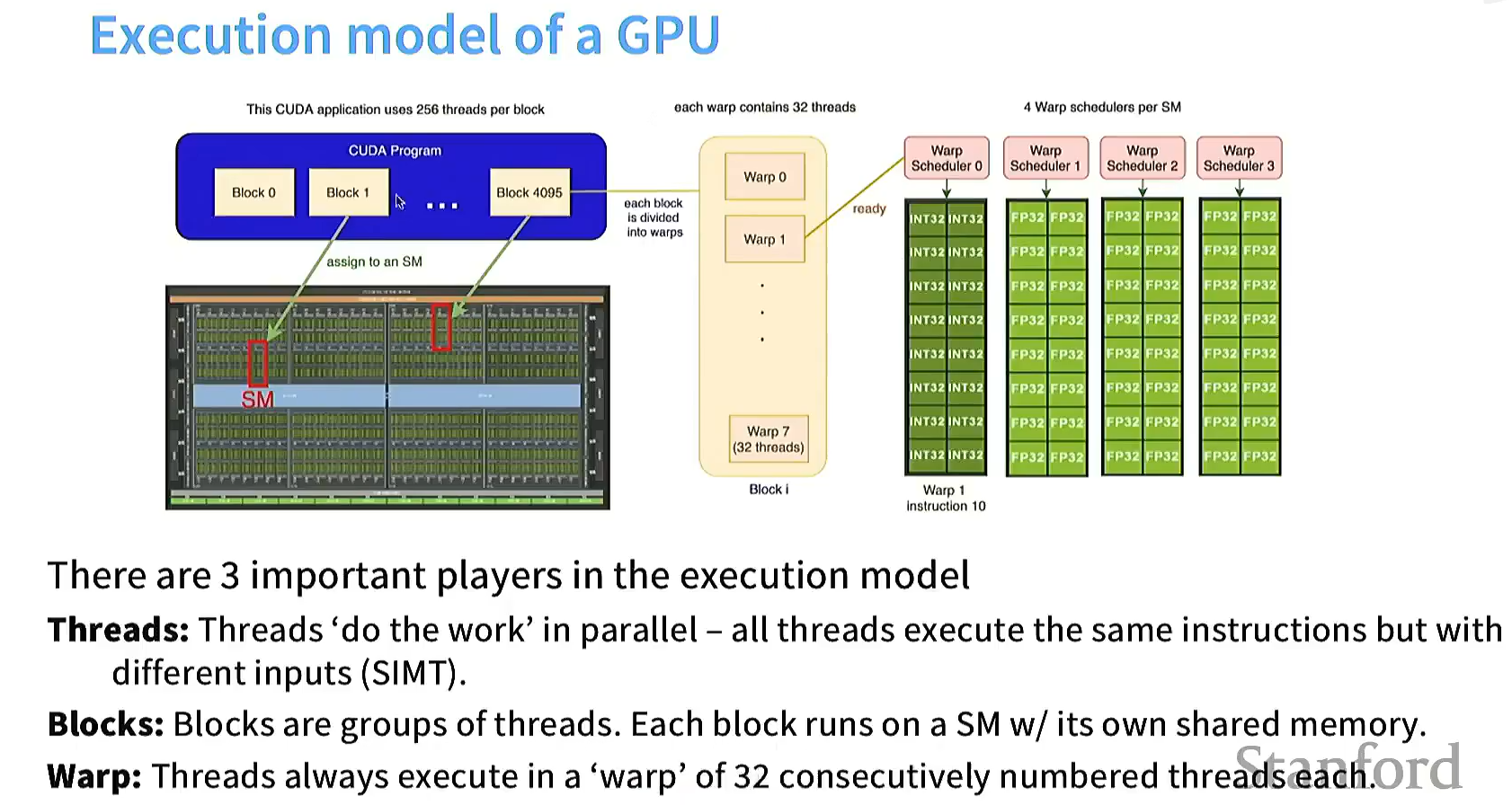
多个SM共享L2 Cache缓存,一个SM内部有多个SP,共享L1 Cache/Shared Memory缓存,每个SP又有自己的寄存器

所以一个block中的线程共享L1 Cache/Shared Memory,但是访问global memory的速度又远远小于访问Shared Memory的速度
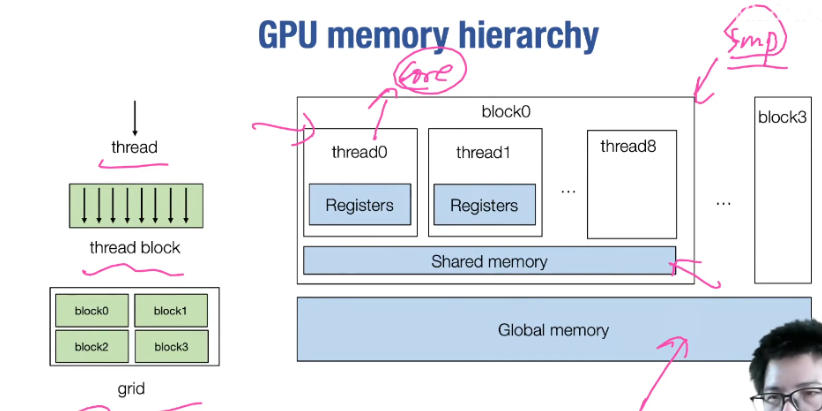
解决办法就是进行矩阵分块,减少global memory的访问
具体的推导过程可以参考:
online softmax:https://zhuanlan.zhihu.com/p/5078640012
flash attention:https://zhuanlan.zhihu.com/p/663932651
flash attention改变的是计算过程,实际的模型结构并没有改变,最终的结果也是一样的
2.6 Continuous Batch
之前介绍的都是单条seq的推理,实际会有多条seq,并且seq的长度不近相同,对于张量Tensor[batch_size, seq_len, hidden_dim],由于每个batch的seq_len不同,所以无法进行批量乘法运算
解决办法也不近相同,可以用padding+mask的方式补齐seq_len,也可以从最小的seq_len开始做prefill然后再decode:
https://github.com/keli-wen/AGI-Study/tree/master/inference/Intro-Basic-LLM-Inference
但是这样就会多出padding部分的不必要的计算量
也可以使用packing的方式,直接变成一个维度Tensor[batch_size * seq_len, hidden_dim],除了attention计算以外的模块都可以这样做,而且方便将prefill和decode放在一起去batch处理
而对于attention的计算,flash attention官方实现中提供了varlen接口,提供cu_seqlen_q,直接在kernel层面避免不必要的计算:
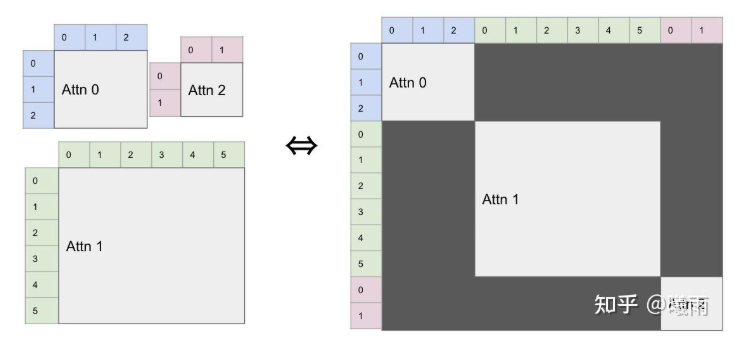
因为不同seq的生成eos的位置不一样,导致短seq的用户要等待长seq的用户,所以使用continuous batch,以seq为单位调度,在生成一批token之后重新进行调度,如果发现有seq生成完了那么就让这个seq结束,从而实现动态的批处理过程
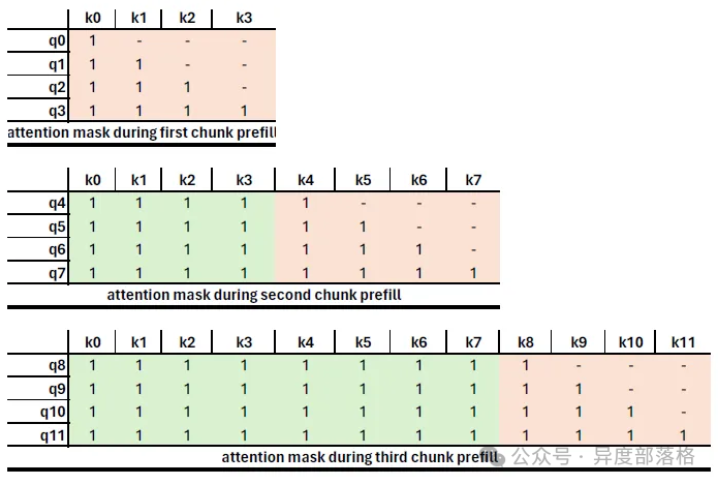
2.7 Chunked Prefill
当上下文长度过大时,如果不对prefill进行拆分,长seq仍然会影响到短seq,所以对prefill阶段进行拆分,可以改善时延,同时也能减少pp并行的GPU气泡,但是会折损prefill的性能,因为要读前一个chunk的kv cache
chunk prefill主要一个是帮助decode,一个是减少pp并行的气泡
通过修改attention mask就可以等价实现
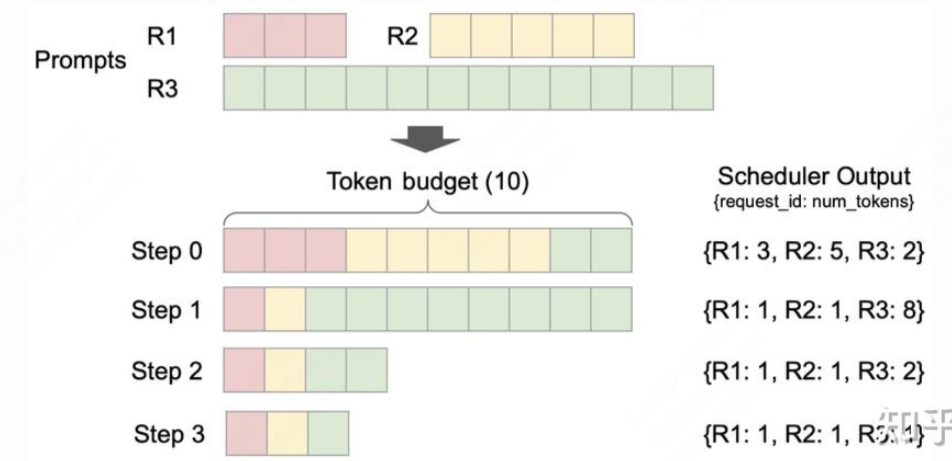
像vllm v1的调度,就是先调度running队列,再调度waiting队列,同时会进行chunked prefill,通过固定token budget,可以保证一个合理的延时
https://zhuanlan.zhihu.com/p/1908153627639551302
2.8 Tensor Parallel
去看开源大模型的实现,会发现基本都有张量并行,就是把模型参数拆分到多个卡上面
以attention模块为例,一般的实现会先根据multi-head拆分,不同GPU负责不同头的attention score计算,例如下图,权重被差分到两个GPU上,一个GPU负责一个头的attention计算,最后在output映射后做一个all reduce的操作,就是累加每个GPU上的结果然后同步
并行方式还有很多种,此处仅作抛砖引玉
- operator: all reduce/reduce/broadcast/all gather/reduce scatter
- data parallelism (memory problem, ZeRO 1/2/3)
- model parallelism: pipeline(zero bubble pipelining) / tensor
- activation parallelism: sequence
- context parallel / ring attention
- expert parallel
- 3d/4d parallel
Appendix:Pytorch Profiler
pytorch profiler 一般针对的是 model forward 过程中的 profiling
from torch.profiler import profile, ProfilerActivity, record_function
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True,
profile_memory=True,
with_stack=True) as prof:
with record_function("model_inference"):
model(inputs)其中activities里面可以添加想捕获的profile类型(ProfilerActivity.CPU / ProfilerActivity.CUDA)
其他参数:
- record_shapes 是否捕获调用函数时输入的tensor张量
- profile_memory 是否捕获内存占用信息
- with_stack 查看调用堆栈
- record_function 里面传入的字符串可以是任意的,可以使用多个record_function用来监控不同的部分
结果打印:
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
prof.export_chrome_trace("trace.json")json文件可以用于chrome://tracing可视化
为避免profiling过程开销太大或者生成的profiling文件太大,可以用schedule来限制:
from torch.profiler import schedule
sort_by_keyword = "self_" + device + "\_time_total"
def trace_handler(p):
output = p.key_averages().table(sort_by=sort_by_keyword, row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace*" + str(p.step_num) + ".json")
with profile(
activities=activities,
schedule=torch.profiler.schedule(wait=1, warmup=1, active=2, repeat=2),
on_trace_ready=trace_handler,
) as p:
for idx in range(8):
model(inputs)
p.step()这个例子中表示,刚开始是wait阶段,调用一遍step()后进入warmup阶段,再调用两遍step()做profiling记录,再调用一遍step()进入下一个循环(重新从wait开始),并且触发trace_handler函数,可以做一些自定义的信息输出。repeat=2表示限制整个循环最多只能进行两轮
应用:
例如如果只想关注注意力计算中的qkv线性变换和算attention的部分,先用record_function做个标注:
def forward(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
) -> torch.Tensor:
with record_function("qkv proj"):
qkv = self.qkv_proj(hidden_states)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q = self.q_norm(q.view(-1, self.num_heads, self.head_dim))
k = self.k_norm(k.view(-1, self.num_kv_heads, self.head_dim))
v = v.view(-1, self.num_kv_heads, self.head_dim)
q, k = self.rotary_emb(positions, q, k)
with record_function("attn"):
o = self.attn(q, k, v)
output = self.o_proj(o.flatten(1, -1))
return output
直接在generate函数处创建prof:
def trace_handler(p):
output = p.key_averages().table(sort_by="cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("trace.json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True,
profile_memory=True,
schedule=torch.profiler.schedule(wait=0, warmup=0, active=5, repeat=1),
on_trace_ready=trace_handler,
) as p:
outputs = llm.generate(prompts, sampling_params, p)然后在llm_engine里面的step后面调用一次step:
while not self.is_finished():
t = perf_counter()
output, num_tokens = self.step()
p.step()这样相当于跟着nano-vllm的调度器做prof了,记录5次的话相当于一次prefill和四次decode:
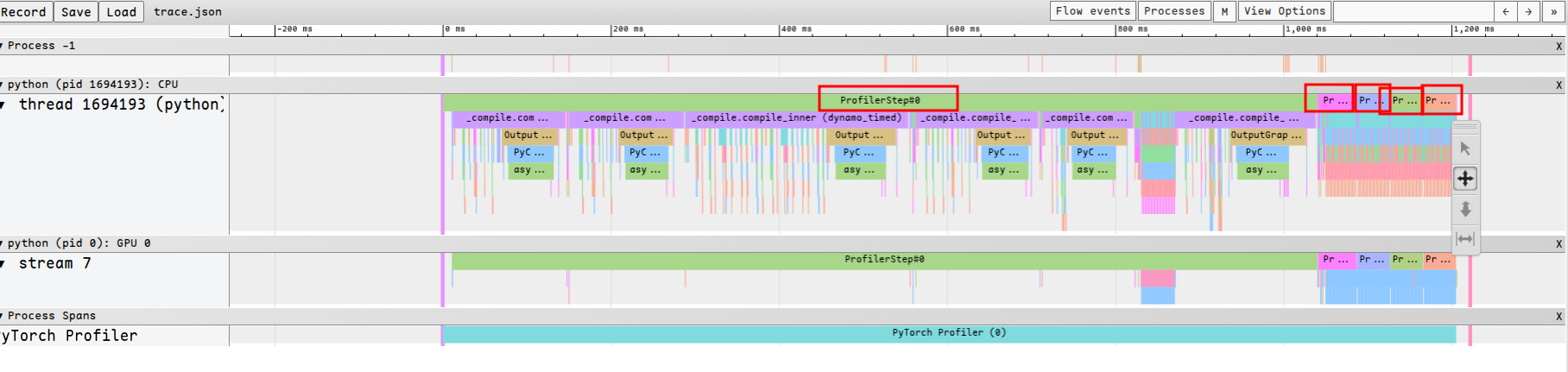
右上角可以搜索自己标注的函数
cuda memory可视化:
torch.cuda.memory._record_memory_history(max_entries=100000)
model(inputs)
# Dump memory snapshot history to a file and stop recording
torch.cuda.memory._dump_snapshot("profile.pkl")
torch.cuda.memory._record_memory_history(enabled=None)导出的文件导入到
https://pytorch.org/memory_viz
这个主要用来观察推理过程中激活值对显存的占据变化,可能需要把kv cache开小一点