pruning技术调研
本文最后更新于 2026年3月19日 下午
Basic
- struct / unstruct / semi-struct
THINK: THINNER KEY CACHE BY QUERY-DRIVEN PRUNING
- 结构化稀疏
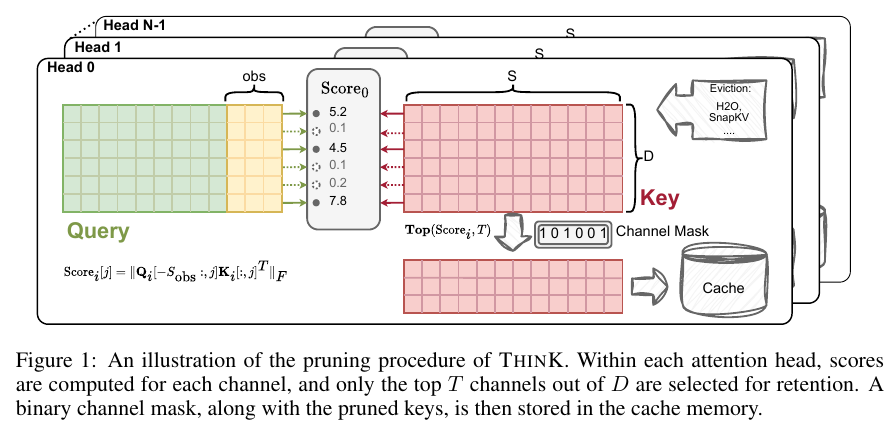
hidden_size维度的稀疏,用mask
- 双kv cache缓存(已剪枝缓存/未剪枝缓存)
Mustafar: Promoting Unstructured Sparsity for KV Cache Pruning in LLM Inference
- 非结构化稀疏
- token维度剪枝 / channel维度剪枝 / Magnitude-based剪枝 / output-aware剪枝
- kv cache的瓦片式存储
- sparse attention kernel
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
- cross layer kv cache合并,层数更深,层之间的kv cache相似度更高
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
- 为非结构化稀疏矩阵乘法高效利用Tensor核心
- 读取稀疏结构,计算稠密结构
- 读取和计算重叠
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
- 球面k-means聚类
OPTIMIZING LLM QUERIES IN RELATIONAL DATA ANALYTICS WORKLOADS
-
llm queries的应用和重排优化
-
todo: flash llm / cpu offloading / cross layer / optimize llm query
KVZIP
context kv cache + [repeat prompt + context]
根据prompt + context找到之前的注意力分数,后面的context相当于一种teacher force
KeyDiff
剪枝与平均K的余弦相似度大的(越接近的)
pruning技术调研
https://gentlecold.top/20250908/pruning/