vLLM最新KV Connector API与推理调用链逐行解析
本文最后更新于 2026年6月24日 下午
1. 先说结论
版本说明:本文最初按2026-05-13访问到的v0.20.2整理;2026-05-17复核vllm-project/vllm远端tag后,稳定tag已经推进到v0.21.0,后面还出现了v0.21.1rc0预发布tag。因此本文把v0.21.0作为“当前最新稳定版”来标注,主调用链仍保留v0.20.2以来的核心结构。KV connector接口在源码里仍明确标注为experimental,所以生产环境要以你实际安装版本的源码和vllm serve --help为准。
一句话概括:
vLLM V1 KV Connector不是一个单纯的数据搬运函数,而是一组横跨scheduler、worker、attention layer、executor输出聚合的双边协议。scheduler侧决定“哪些外部KV可用、该给哪些block预留位置、要把什么metadata发给worker”;worker侧根据metadata在forward前后执行load/save,并把完成状态、失败block、统计信息回传给scheduler。
从推理过程看,KV connector主要插在四个位置:
- 请求第一次进入调度时,scheduler调用
get_num_new_matched_tokens()查询外部KV命中。 - scheduler分配GPU KV block后,调用
update_state_after_alloc()让connector记录load/store计划。 - scheduler生成
SchedulerOutput时,调用build_connector_meta()把计划封装成metadata,随本轮调度输出发给worker。 - worker执行模型时,forward前调用
start_load_kv(),attention层入口/出口调用wait_for_layer_load()和save_kv_layer(),forward后调用wait_for_save()、get_finished()和build_connector_worker_meta()回报结果。
这套接口同时服务几类场景:
- P/D disaggregation:prefill worker算完KV,decode worker远程读取KV。典型实现是
NixlConnector、MooncakeConnector。 - 本地或外部KV offload:把GPU KV cache搬到CPU、文件系统、LMCache等外部存储,再按prefix cache命中读回来。典型实现是
SimpleCPUOffloadConnector、OffloadingConnector、LMCacheConnectorV1、HF3FSKVConnector。 - 调试和实验connector:例如
ExampleConnector、DecodeBenchConnector。 - 组合connector:
MultiConnector可以组合多个connector。
先给最核心的生命周期图:
sequenceDiagram
participant Q as Request
participant S as V1 Scheduler
participant C as Scheduler-side Connector
participant W as Worker-side Connector
participant A as Attention Layer
participant X as External KV Store/Remote Worker
Q->>S: add_request()
S->>S: local prefix cache lookup
S->>C: get_num_new_matched_tokens(request, local_hit)
C-->>S: (external_tokens, load_kv_async)
S->>S: allocate_slots(..., delay_cache_blocks=load_kv_async)
S->>C: update_state_after_alloc(request, blocks, external_tokens)
S->>C: build_connector_meta(scheduler_output)
C-->>S: KVConnectorMetadata
S-->>W: SchedulerOutput.kv_connector_metadata
W->>W: bind_connector_metadata()
W->>W: handle_preemptions()
W->>X: start_load_kv()
A->>W: wait_for_layer_load(layer)
A->>A: attention forward, write/read paged KV
A->>W: save_kv_layer(layer, kv_cache, attn_metadata)
W->>W: wait_for_save()
W->>S: KVConnectorOutput(finished_recving/sending/errors/stats)
S->>C: update_connector_output(output)
S->>S: promote WAITING_FOR_REMOTE_KVS or free delayed blocks2. KVTransferConfig:打开connector的入口
先看配置入口:vllm/config/kv_transfer.py。
KVTransferConfig的核心字段在v0.21.0里包括:
kv_connector: str | None = None
engine_id: str | None = None
kv_buffer_device: str = ...
kv_buffer_size: float = 1e9
kv_role: KVRole | None = None
kv_rank: int | None = None
kv_parallel_size: int = 1
kv_ip: str = "127.0.0.1"
kv_port: int = 14579
kv_connector_extra_config: dict[str, Any] = field(default_factory=dict)
kv_connector_module_path: str | None = None
enable_permute_local_kv: bool = False
kv_load_failure_policy: Literal["recompute", "fail"] = "fail"逐行解释:
kv_connector是connector名字,比如NixlConnector、LMCacheConnectorV1、SimpleCPUOffloadConnector。engine_id是当前vLLM实例在KV传输协议里的身份。如果用户不传,__post_init__()会生成UUID。kv_buffer_device描述connector临时buffer放在哪里。NIXL这类connector可能用cuda直接注册GPU内存,也可能用cpu做host staging buffer。kv_role有kv_producer、kv_consumer、kv_both。P/D拆分里prefill侧通常生产KV,decode侧消费KV;offload场景常用kv_both。kv_rank和kv_parallel_size主要服务早期或特定connector的并行实例配置。kv_ip、kv_port给分布式connector建立side channel或通信组用。kv_connector_extra_config是各connector自定义参数的入口。例如CPU offload的容量、NIXL backend、是否启用cross-layer blocks等。kv_connector_module_path允许动态加载外部connector。也就是说用户可以不改vLLM源码,只要给模块路径和类名。kv_load_failure_policy控制外部KV加载失败后怎么办:fail直接失败请求,recompute则把失败block对应token退回去重新算。
__post_init__()里有两个关键检查:
- 没有
engine_id就自动生成。 - 只要设置了
kv_connector,就必须设置kv_role。
所以最小配置不是只写connector名字,而是至少要能表达:
KVTransferConfig(
kv_connector="NixlConnector",
kv_role="kv_both",
)实际部署通常会更多,例如:
{
"kv_connector": "NixlConnector",
"kv_role": "kv_both",
"kv_buffer_device": "cuda",
"kv_connector_extra_config": {
"backends": ["UCX"]
}
}3. Factory:名字如何变成connector对象
入口是vllm/distributed/kv_transfer/kv_connector/factory.py。
KVConnectorFactory做三件事:
- 维护一个
name -> lazy loader注册表。 - 根据
KVTransferConfig.kv_connector找到类。 - 分别创建scheduler侧和worker侧connector。
关键逻辑:
connector_cls, compat_sig = cls._get_connector_class_with_compat(kv_transfer_config)
hma_enabled = not config.scheduler_config.disable_hybrid_kv_cache_manager
if hma_enabled and not supports_hma(connector_cls):
raise ValueError(...)
...
return connector_cls(config, role, kv_cache_config)逐行解释:
_get_connector_class_with_compat()先看内置注册表。- 如果注册表没有,再看
kv_connector_module_path,动态importlib.import_module()加载外部模块。 compat_sig是兼容旧签名用的。新connector应该实现__init__(vllm_config, role, kv_cache_config)。- vLLM默认启用Hybrid KV Cache Manager时,connector类必须实现
SupportsHMA,否则会要求用户设置--disable-hybrid-kv-cache-manager。 - 同一个connector类会被创建两次:scheduler进程里
role=SCHEDULER,worker进程里role=WORKER。接口上强制分离,是为了避免scheduler直接碰GPU KV tensor,也避免worker直接改调度状态。
截至v0.21.0,内置注册名包括:
| Connector | 典型用途 |
|---|---|
ExampleConnector |
调试/教学,把KV写到共享存储 |
ExampleHiddenStatesConnector |
hidden states传输示例 |
P2pNcclConnector |
NCCL P2P风格KV传输 |
LMCacheConnectorV1 |
接LMCache |
LMCacheMPConnector |
LMCache多进程connector |
NixlConnector |
基于NIXL的P/D远程KV传输 |
MultiConnector |
组合多个connector |
MoRIIOConnector |
MoRIIO相关connector |
OffloadingConnector |
vLLM native offloading connector |
DecodeBenchConnector |
decode benchmark |
MooncakeConnector |
Mooncake传输 |
FlexKVConnectorV1 |
FlexKV |
SimpleCPUOffloadConnector |
简化版CPU KV offload |
HF3FSKVConnector |
HF3FS KV connector |
NixlConnector在v0.21.0里已经从单文件重构为包路径:
vllm.distributed.kv_transfer.kv_connector.v1.nixl内部再分成connector.py、scheduler.py、worker.py、metadata.py等文件。
4. KVConnectorBase_V1:API逐行拆解
核心抽象在vllm/distributed/kv_transfer/kv_connector/v1/base.py。
4.1 文件头注释其实就是协议说明
文件开头把接口分成scheduler-side和worker-side。
Scheduler-side:
get_num_new_matched_tokens():查询远端或外部KV cache里命中了多少新token。update_state_after_alloc():CacheManager给请求分配block之后,connector记录这些block如何用于load/store。update_connector_output():worker侧回传结果后,scheduler侧connector更新内部状态。request_finished():请求结束时调用,connector决定是否需要延迟释放block。take_events():输出KV cache事件,用于监控/事件发布。
Worker-side:
handle_preemptions():block被覆盖前处理正在异步保存的数据。start_load_kv():开始把KV加载进vLLM paged KV buffer。wait_for_layer_load():某一层attention执行前,等待这一层KV加载完成。save_kv_layer():attention层执行后,把这一层KV保存出去。wait_for_save():forward结束时等待保存完成。get_finished():返回哪些请求完成了异步send/recv。build_connector_worker_meta():返回worker侧metadata给scheduler侧connector。
4.2 CopyBlocksOp:host staging的复制抽象
CopyBlocksOp签名是:
Callable[
[
dict[str, torch.Tensor],
dict[str, torch.Tensor],
list[int],
list[int],
Literal["h2d", "d2h"],
],
None,
]这不是通用tensor copy,而是“按KV block id复制”的函数:
- 第一个dict是源KV cache tensor集合。
- 第二个dict是目标KV cache tensor集合。
s_indices是源block id列表。d_indices是目标block id列表。direction是host-to-device或device-to-host。
NIXL在不能直接注册设备内存或配置了CPU buffer时,会用这个函数在GPU KV cache和host staging buffer之间搬block。
4.3 SupportsHMA:新KV cache manager下的多group支持
SupportsHMA只定义一个方法:
request_finished_all_groups(request, block_ids)为什么需要它?
现在vLLM的KV cache不一定只有一种block group。全注意力、sliding window、Mamba/SSM、不同层组可能有不同block布局。旧的request_finished(request, list[int])只适合单group。HMA打开时,connector必须能处理:
tuple[list[int], ...]也就是每个KV cache group一组block ids。
Factory里会检查:
hma_enabled = not disable_hybrid_kv_cache_manager
if hma_enabled and not supports_hma(connector_cls):
raise ValueError(...)因此新connector最好直接继承SupportsHMA,实现request_finished_all_groups()。
4.4 KVConnectorRole:同一个类,两种身份
KVConnectorRole只有两个值:
SCHEDULER = 0
WORKER = 1这意味着connector类通常长这样:
if role == KVConnectorRole.SCHEDULER:
self.scheduler_impl = ...
self.worker_impl = None
else:
self.scheduler_impl = None
self.worker_impl = ...NixlConnector就是这种薄门面:scheduler方法转发到NixlConnectorScheduler,worker方法转发到NixlConnectorWorker。
4.5 三类metadata
base.py里有三类metadata:
KVConnectorHandshakeMetadata:out-of-band握手用。例如NIXL worker把agent name、内存region、端口等信息给对端。KVConnectorMetadata:scheduler发给worker的本轮执行计划。KVConnectorWorkerMetadata:worker回传给scheduler的补充状态。
KVConnectorWorkerMetadata要求实现:
aggregate(self, other)因为一个engine step可能有多个worker、多个TP rank、多个DP rank,executor会先聚合worker metadata,再给scheduler侧connector。
4.6 初始化:实验接口、必须有KVTransferConfig
KVConnectorBase_V1.__init__()做几件事:
- 打warning:这个API仍是experimental。
- 保存
_connector_metadata = None。 - 保存
_vllm_config。 - 从
vllm_config.kv_transfer_config取_kv_transfer_config;如果没有就报错。 - 保存
_kv_cache_config。 - 如果
kv_cache_config是None,打deprecated warning。 - 保存
_role。
重点是:新connector不能假设没有KVTransferConfig也能跑。只要走KVConnectorBase_V1,kv_transfer_config就是必需项。
4.7 metadata绑定:worker侧每步都要bind/clear
worker侧有三个小方法:
bind_connector_metadata(connector_metadata)
clear_connector_metadata()
_get_connector_metadata()调用关系是:
- model runner在forward前从
SchedulerOutput取metadata。 - 调
bind_connector_metadata()放到connector内部。 - connector的
start_load_kv()、save_kv_layer()等方法从_get_connector_metadata()读取本轮计划。 - forward结束后调用
clear_connector_metadata(),避免下一轮误用旧metadata。
这也是has_connector_metadata()存在的原因:attention layer hook会检查当前是否真的绑定了metadata。没有metadata时,hook直接变成no-op。
4.8 register_kv_caches与cross-layer blocks
worker初始化KV cache后,会把KV cache tensor注册给connector:
register_kv_caches(kv_caches: dict[str, torch.Tensor])普通布局下,dict key通常是layer name,value是该层KV cache tensor。
另一个接口是:
register_cross_layers_kv_cache(kv_cache, attn_backend)它服务prefer_cross_layer_blocks=True的connector。意思是把多层KV放在一个带num_layers维度的大tensor里。NIXL在v0.21.0里会根据backend、KV cache layout、extra config决定是否偏好cross-layer blocks。
为什么有这个优化?
普通逐层KV cache搬运可能是:
layer0 block7
layer1 block7
layer2 block7
...cross-layer blocks可以把同一个block在多层上的数据放得更连续,减少注册和transfer描述符数量,对远程搬运更友好。
4.9 worker侧四个核心方法
start_load_kv()
start_load_kv(forward_context, **kwargs)语义:forward开始前,根据metadata启动load。
它不一定阻塞。NIXL会触发非阻塞远程读;SimpleCPUOffload甚至把实际copy延迟到get_finished()里提交;ExampleConnector会同步从文件读入KV。
wait_for_layer_load()
wait_for_layer_load(layer_name)语义:attention layer真正要读KV前,确保当前层需要的KV已经在paged KV buffer里。
如果connector是全量forward前加载,方法可以是no-op。如果connector做layer-by-layer pipeline,这里就是同步点。
save_kv_layer()
save_kv_layer(layer_name, kv_layer, attn_metadata, **kwargs)语义:attention layer结束后,把本层KV保存到外部系统。
注意这里传的是整层paged KV buffer和attention metadata。connector要根据slot mapping、block table、metadata判断哪些token/block属于本轮需要保存。
wait_for_save()
wait_for_save()语义:forward退出前确保保存动作不会和后续KV block复用发生数据竞争。
如果connector使用异步store并通过额外ref count保护block,可以不在这里阻塞;但如果没有保护,就必须等待。
4.10 get_finished()和错误上报
get_finished(finished_req_ids)返回:
(finished_sending, finished_recving)含义:
finished_sending:这些请求之前的send/save已经完成,scheduler可以释放被connector延迟持有的block。finished_recving:这些请求的load/recv已经完成,scheduler可以把WAITING_FOR_REMOTE_KVS请求重新放回可调度状态。
另一个关键方法:
get_block_ids_with_load_errors()它返回加载失败的外部KV block id。scheduler收到后会按kv_load_failure_policy处理:
fail:请求失败。recompute:撤销这些外部命中的token,重新计算。
4.11 scheduler侧三个抽象方法
get_num_new_matched_tokens()
get_num_new_matched_tokens(request, num_computed_tokens) -> tuple[int | None, bool]返回两个值:
- 外部KV cache在
num_computed_tokens之后还能额外命中多少token。 - 是否异步加载。
三个细节很重要:
- 这个方法可能对同一个请求调用多次,所以应该side-effect free。
- 返回
None表示connector暂时还无法判断命中长度,scheduler会跳过该请求,后面再问。 - 如果命中token数是0,第二个返回值必须是
False。
例如本地prefix cache已经命中64个token,外部CPU cache又能命中128个token,那么返回:
(128, True)如果是同步加载connector,也可以返回:
(128, False)区别在scheduler行为里会看到。
update_state_after_alloc()
update_state_after_alloc(request, blocks, num_external_tokens)这个方法在CacheManager分配block之后调用。connector在这里知道:
- 哪个请求需要load。
- 外部命中了多少token。
- 这些token对应的目标GPU block ids是什么。
如果get_num_new_matched_tokens()返回异步加载,这个方法可能对同一个请求调用两次:第一次为外部KV预留block;load完成后请求重新调度,第二次为后续新计算token分配block。
build_connector_meta()
build_connector_meta(scheduler_output) -> KVConnectorMetadata这个方法把scheduler侧connector内部暂存的load/store计划封装成metadata。注释特别强调两点:
- 不应该修改
scheduler_output字段。 - 调用后会reset connector内部状态。
换句话说,update_state_after_alloc()是在逐请求积累计划,build_connector_meta()是在本轮调度结束时一次性打包。
4.12 request_finished():谁负责释放block
request_finished(request, block_ids) -> tuple[bool, dict[str, Any] | None]返回值第一项很关键:
False:scheduler可以现在释放block。True:connector接管这些block的生命周期,等未来get_finished()返回该request id后scheduler再释放。
第二项是kv_transfer_params,会进入请求输出。P/D disaggregation里,prefill侧结束后通常会把远端读取所需的参数返回给上层router或decode侧,例如remote block ids、remote engine id、host、port等。
5. KVConnectorBase_V1函数速查表与调用时序图
这一节把KVConnectorBase_V1和base.py里相关小接口的函数按调用位置完整过一遍。前面讲的是重点调用链,这里更像查表:写connector时可以逐项对照“谁调用、什么时候调用、默认行为是什么”。
5.1 初始化、属性和layout能力声明
| 函数/属性 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
__init__(vllm_config, role, kv_cache_config) |
KVConnectorFactory |
保存配置、角色、KV cache配置,并要求kv_transfer_config存在 |
如果没有kv_transfer_config直接报错 |
role |
connector内部或调试代码 | 返回当前实例是scheduler侧还是worker侧 |
返回self._role |
prefer_cross_layer_blocks |
worker初始化KV cache时 | 声明connector是否希望使用cross-layer KV layout | False |
get_required_kvcache_layout(vllm_config) |
配置/初始化检查 | 声明connector强制要求HND或NHD等KV layout |
None |
requires_piecewise_for_cudagraph(extra_config) |
配置检查 | 如果connector依赖layer-wise Python hook,需要FULL CUDA graph降级到PIECEWISE | False |
这里最容易混的是prefer_cross_layer_blocks和get_required_kvcache_layout()。前者说的是“是否希望把多层KV放进一个cross-layer大tensor”,后者说的是“单层KV内部head/token维度要用什么layout”。NIXL通常会要求或偏好特定layout,是为了让远程传输时block更连续、描述符更少。
5.2 worker侧metadata生命周期
| 函数 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
bind_connector_metadata(connector_metadata) |
model runner forward前 | 把SchedulerOutput.kv_connector_metadata绑定到worker connector |
保存到self._connector_metadata |
clear_connector_metadata() |
model runner forward后 | 清理本轮metadata,防止下一轮误用 | 置空 |
_get_connector_metadata() |
connector内部 | 读取当前step的metadata | 没绑定时assert失败 |
has_connector_metadata() |
attention hook/connector辅助逻辑 | 判断当前是否有有效metadata | 返回是否非空 |
这组函数是worker侧每个engine step的上下文开关。scheduler侧把计划封装成metadata,worker侧先bind,然后start_load_kv()、save_kv_layer()等方法都从这里读本轮计划。
5.3 worker侧KV cache注册和host buffer拷贝
| 函数 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
register_kv_caches(kv_caches) |
worker初始化KV cache后 | 把每层KV cache tensor交给connector,便于注册内存或建立索引 | no-op |
register_cross_layers_kv_cache(kv_cache, attn_backend) |
启用cross-layer layout时 | 注册一个包含所有层KV的大tensor | no-op |
set_host_xfer_buffer_ops(copy_operation) |
worker初始化connector后 | 注入GPU KV cache和CPU host staging buffer之间的block copy函数 | no-op |
set_host_xfer_buffer_ops()不是让vLLM接管host buffer。以NIXL为例,host staging buffer由connector分配和管理;vLLM只是把copy_kv_blocks()这种平台相关的“按block做h2d/d2h copy”的函数传进去。
5.4 worker侧load/save主路径
| 函数 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
handle_preemptions(kv_connector_metadata) |
model runner执行前 | 在block被抢占/覆盖前处理未完成的异步save | no-op |
start_load_kv(forward_context, **kwargs) |
forward开始前 | 启动外部KV到vLLM paged KV buffer的load | 抽象方法,必须实现 |
wait_for_layer_load(layer_name) |
attention layer执行前 | 等当前层需要的KV load完成 | 抽象方法,必须实现 |
save_kv_layer(layer_name, kv_layer, attn_metadata, **kwargs) |
attention layer执行后 | 把本层新KV保存到外部系统 | 抽象方法,必须实现 |
wait_for_save() |
forward结束时 | 等save完成,避免KV block被复用时数据还没保存完 | 抽象方法,必须实现 |
get_finished(finished_req_ids) |
forward后收集connector输出 | 返回已完成异步send/save和recv/load的请求id | (None, None) |
get_block_ids_with_load_errors() |
forward后收集connector输出 | 返回load失败的block ids,供scheduler fail或recompute | 空集合 |
shutdown() |
worker退出 | 清理线程、网络连接、异步copy等资源 | no-op |
这组函数是真正的数据路径。同步connector可以在start_load_kv()里把KV全部加载好,wait_for_layer_load()变成no-op;异步connector则可能在start_load_kv()里提交DMA/RDMA,在wait_for_layer_load()里做细粒度同步。
5.5 worker侧统计、事件和回传metadata
| 函数 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
get_kv_connector_stats() |
forward后 | 返回本周期connector传输统计 | None |
get_kv_connector_kv_cache_events() |
forward后 | 返回connector侧产生的KV cache events | None |
get_handshake_metadata() |
worker握手阶段 | 返回对端需要的out-of-band握手信息 | None |
build_connector_worker_meta() |
forward后 | 构造worker回传给scheduler-side connector的metadata | None |
get_finished()只能表达“哪些请求完成了send/recv”。如果connector还要回传更细的状态,例如某个store event在所有TP rank都完成了,就要用build_connector_worker_meta()和KVConnectorWorkerMetadata.aggregate()。
5.6 scheduler侧调度主路径
| 函数 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
get_num_new_matched_tokens(request, num_computed_tokens) |
scheduler调度waiting request时 | 查询外部KV cache还能命中多少token,以及是否异步load | 抽象方法,必须实现 |
update_state_after_alloc(request, blocks, num_external_tokens) |
scheduler分配block后 | 告诉connector本请求拿到了哪些本地block,便于生成load/store计划 | 抽象方法,必须实现 |
build_connector_meta(scheduler_output) |
scheduler生成SchedulerOutput前 |
把本轮connector计划打包成KVConnectorMetadata发给worker |
抽象方法,必须实现 |
update_connector_output(connector_output) |
scheduler处理worker输出时 | 消费worker侧回传的完成状态、worker metadata、统计等 | no-op |
request_finished(request, block_ids) |
请求完成、释放block前 | 决定connector是否要延迟释放这些block,并可返回kv_transfer_params |
(False, None) |
take_events() |
scheduler每步末尾 | 取connector产生的KV cache events并发布 | 空迭代器 |
其中get_num_new_matched_tokens()要尽量保持side-effect free。scheduler可能因为预算、LoRA限制、block不足、异步load完成等原因,对同一个请求多次询问外部命中。
5.7 多worker聚合、指标和cache控制
| 函数/接口 | 调用方 | 作用 | 默认行为 |
|---|---|---|---|
get_finished_count() |
KVOutputAggregator初始化 |
覆盖默认按world_size聚合完成数的逻辑 |
None |
build_kv_connector_stats(data) |
executor/统计聚合路径 | 从dict构造connector自定义stats对象 | None |
set_xfer_handshake_metadata(metadata) |
engine握手完成后 | 把其他worker/engine的握手metadata注入本connector | no-op |
build_prom_metrics(vllm_config, metric_types, labelnames, per_engine_labelvalues) |
metrics初始化 | 注册connector自定义Prometheus指标 | None |
reset_cache() |
reset prefix/cache相关路径 | 重置connector内部cache | 记录debug并返回None |
SupportsHMA.request_finished_all_groups(request, block_ids) |
HMA开启时请求完成路径 | 多KV cache group版本的request_finished() |
实现类必须提供 |
supports_hma(connector) |
KVConnectorFactory |
判断connector类或实例是否继承/实现SupportsHMA |
返回布尔值 |
KVConnectorWorkerMetadata.aggregate(other) |
executor聚合worker输出 | 多worker/多rank的worker metadata合并 | 实现类必须提供 |
get_finished_count()常见于完成事件不等于world_size的connector。例如某些传输只需要一个rank回报,或者connector内部已经做过聚合,就不能让executor再按所有worker强行等待。
5.8 全函数调用时序图
下面这张图把base.py里所有主要函数放到生命周期里。实线是主路径,虚线是可选能力或只在特定配置下调用。
sequenceDiagram
participant F as KVConnectorFactory/Engine Init
participant S as Scheduler-side Connector
participant E as Engine/Scheduler
participant W as Worker-side Connector
participant M as ModelRunner/Attention
participant X as Remote KV / Host Buffer / External Cache
participant O as Executor/Aggregator/Metrics
F->>S: __init__(..., role=SCHEDULER, ...)
F->>W: __init__(..., role=WORKER, ...)
F->>S: get_required_kvcache_layout()
F->>S: requires_piecewise_for_cudagraph()
F->>W: prefer_cross_layer_blocks
alt 普通per-layer KV cache
M->>W: register_kv_caches(kv_caches)
else cross-layer KV cache
M->>W: register_cross_layers_kv_cache(kv_cache, attn_backend)
end
M->>W: set_host_xfer_buffer_ops(copy_kv_blocks)
W-->>E: get_handshake_metadata()
E->>S: set_xfer_handshake_metadata(all_worker_metadata)
O->>S: build_prom_metrics(...)
loop 每个scheduler step
E->>S: get_num_new_matched_tokens(request, local_hit)
S-->>E: (external_tokens, load_kv_async)
E->>E: allocate_slots(...)
E->>S: update_state_after_alloc(request, blocks, external_tokens)
E->>S: build_connector_meta(scheduler_output)
S-->>E: KVConnectorMetadata
E->>M: execute_model(SchedulerOutput)
M->>W: bind_connector_metadata(metadata)
M->>W: handle_preemptions(metadata)
M->>W: has_connector_metadata()
M->>W: start_load_kv(forward_context)
W-->>X: submit/load/read KV
loop 每个attention layer
M->>W: wait_for_layer_load(layer_name)
M->>M: attention forward
M->>W: save_kv_layer(layer_name, kv_layer, attn_metadata)
W-->>X: submit/save/write KV
end
M->>W: wait_for_save()
M->>W: get_finished(finished_req_ids)
M->>W: get_block_ids_with_load_errors()
M->>W: get_kv_connector_stats()
M->>W: get_kv_connector_kv_cache_events()
M->>W: build_connector_worker_meta()
M->>W: clear_connector_metadata()
W-->>O: KVConnectorOutput
O->>O: KVConnectorWorkerMetadata.aggregate()
O->>S: update_connector_output(connector_output)
O->>S: build_kv_connector_stats(data)
E->>S: take_events()
end
E->>S: request_finished(request, block_ids)
alt HMA / multiple kv_cache_groups
E->>S: request_finished_all_groups(request, block_id_groups)
end
O->>S: get_finished_count()
E->>S: reset_cache()
E->>W: shutdown()这张图里有两个容易忽略的点:
register_kv_caches()和register_cross_layers_kv_cache()二选一。启用cross-layer blocks时,vLLM内部实际分配的是一个跨层大tensor,然后给每层attention切view。get_handshake_metadata()和set_xfer_handshake_metadata()不是每个connector都需要。NIXL、Mooncake这类跨进程/跨机器connector需要交换地址、agent、memory region等信息;纯本地CPU offload可能不需要。
6. Scheduler推理调用链逐行讲解
下面看vllm/v1/core/sched/scheduler.py。
6.1 Scheduler初始化时创建scheduler-side connector
初始化阶段的关键代码:
if self.vllm_config.kv_transfer_config is not None:
self.connector = KVConnectorFactory.create_connector(
config=self.vllm_config,
role=KVConnectorRole.SCHEDULER,
kv_cache_config=self.kv_cache_config,
)
kv_load_failure_policy = self.vllm_config.kv_transfer_config.kv_load_failure_policy
self.recompute_kv_load_failures = kv_load_failure_policy == "recompute"逐行解释:
- 只要
kv_transfer_config不为None,scheduler就创建connector。 role=KVConnectorRole.SCHEDULER保证创建的是scheduler侧逻辑。kv_cache_config传进去,让connector知道block size、group、layout等信息。kv_load_failure_policy被转换成布尔值recompute_kv_load_failures,后续处理失败block时使用。
注意:这里还禁止encoder-decoder模型使用KV connector,因为相关路径还没有完整支持。
6.2 第一次调度请求:先查本地cache,再查外部cache
在waiting队列调度新请求时,核心代码从request.num_computed_tokens == 0开始。
第一步:本地prefix cache命中。
new_computed_blocks, num_new_local_computed_tokens = (
self.kv_cache_manager.get_computed_blocks(request)
)含义:
new_computed_blocks是本地GPU prefix cache命中的block。num_new_local_computed_tokens是这些block对应的token数。
第二步:如果有connector,继续查外部KV cache。
ext_tokens, load_kv_async = (
self.connector.get_num_new_matched_tokens(
request, num_new_local_computed_tokens
)
)这里传入的是“本地已经命中的token数”。connector只需要回答在这个基础之后还能命中多少外部token。
如果ext_tokens is None:
request_queue.pop_request()
step_skipped_waiting.prepend_request(request)
continue这表示connector暂时无法回答,比如远程索引查询还没返回。scheduler不阻塞整个step,而是把请求放进skipped waiting,下轮再试。
如果命中成功:
num_external_computed_tokens = ext_tokens
num_computed_tokens = num_new_local_computed_tokens + num_external_computed_tokens也就是说,对scheduler来说:
已经可视为computed的token = 本地prefix cache命中 + 外部KV命中在v0.21.0里,prefill统计也在这里记录:
request.prefill_stats.set(
num_prompt_tokens=request.num_prompt_tokens,
num_local_cached_tokens=num_new_local_computed_tokens,
num_external_cached_tokens=num_external_computed_tokens,
)这就是为什么指标里能区分本地cache hit和external KV transfer。
6.3 异步load时,本轮不算新token
如果connector返回load_kv_async=True:
assert num_external_computed_tokens > 0
num_new_tokens = 0含义:
- 本轮只发起外部KV加载。
- 不把该请求放进真正要跑模型计算的batch。
- 这样可以让远程KV传输和其他请求的GPU compute重叠。
如果不是异步load:
num_new_tokens = request.num_tokens - num_computed_tokens
...
num_new_tokens = min(num_new_tokens, token_budget)也就是直接把外部命中视作已经就绪,然后继续调度剩余token计算。
6.4 allocate_slots:给外部KV预留GPU block
异步load最容易误解的点,是“外部KV已经命中”并不等于“GPU里已经有KV”。scheduler只能先把目标位置占住,再把搬运计划交给worker执行。下面这张图把这条链路展开:
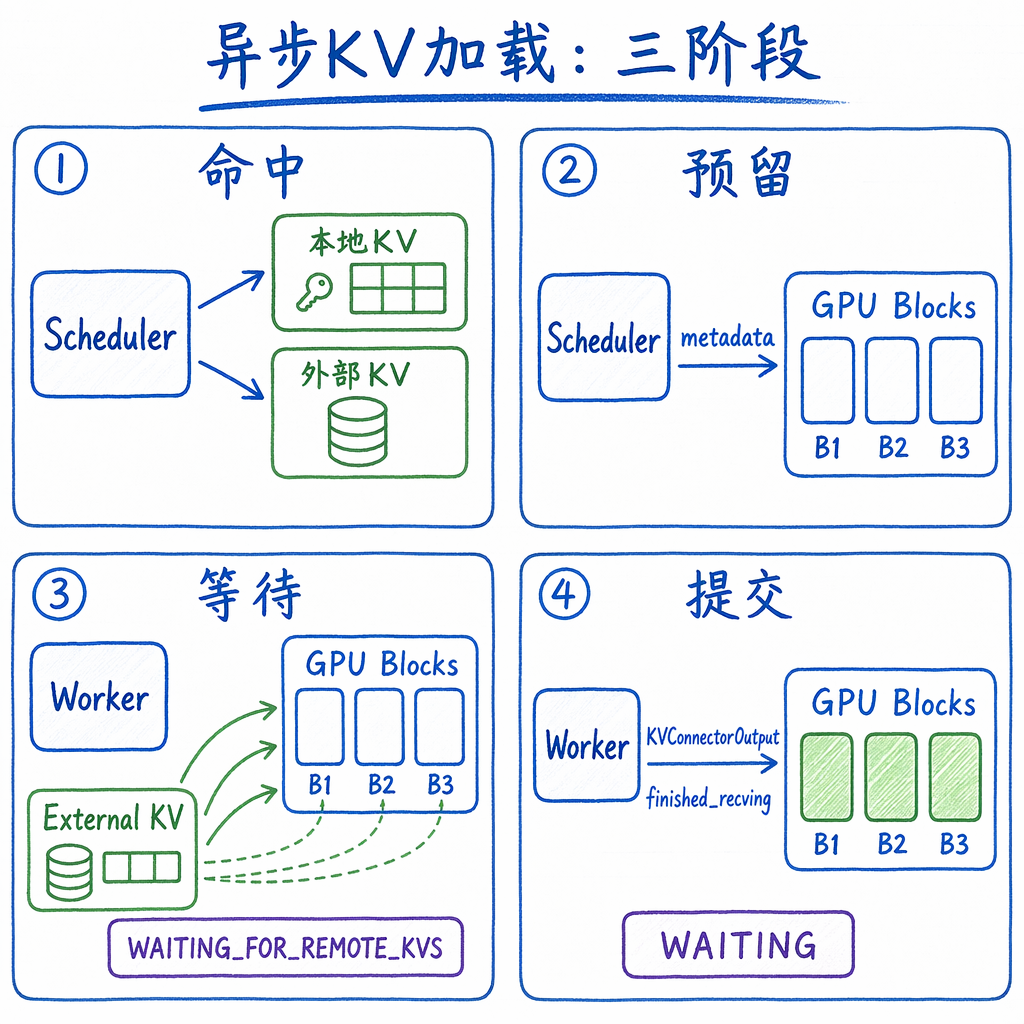
无论同步还是异步,scheduler都要给请求分配KV block:
new_blocks = self.kv_cache_manager.allocate_slots(
request,
num_new_tokens,
num_new_computed_tokens=num_new_local_computed_tokens,
new_computed_blocks=new_computed_blocks,
num_lookahead_tokens=effective_lookahead_tokens,
num_external_computed_tokens=num_external_computed_tokens,
delay_cache_blocks=load_kv_async,
num_encoder_tokens=num_encoder_tokens,
)逐项解释:
num_new_tokens:本轮真正要计算的新token数。异步load时是0。num_new_computed_tokens:本地prefix cache命中token数。new_computed_blocks:本地命中的block对象。num_external_computed_tokens:外部KV命中token数。delay_cache_blocks=load_kv_async:异步load时,block先分配但不能马上放进prefix cache,因为数据还没到。
这一点非常关键:外部KV命中不是只改一个计数,还必须为即将读入的KV准备GPU block位置。
可以把这里理解成两份账本:
request.num_computed_tokens是调度账本,表示“只要KV成功搬进来,这些token就不必重新算”。delay_cache_blocks=True保护的是cache账本,表示“这些GPU block虽然已经分配给请求,但数据尚未到达,不能加入prefix cache,也不能被其他请求当作可复用命中”。
只有worker后面通过KVConnectorOutput.finished_recving确认搬运完成,scheduler才会把这些block正式纳入本地prefix cache体系。
因此异步load路径里存在三个阶段:命中被承认、block被预留、cache被提交。把这三件事分开,才能避免“外部命中了512个token,为什么本轮还不继续算”的困惑。
6.5 update_state_after_alloc:connector拿到目标block
分配成功后:
self.connector.update_state_after_alloc(
request,
self.kv_cache_manager.get_blocks(request_id),
num_external_computed_tokens,
)这一步把request和分配好的block交给connector。
以NIXL为例,decode侧会在这里记录:
这个请求要从remote_block_ids读KV,
读到本地local_block_ids里。以SimpleCPUOffload为例,会在这里找到CPU cache命中的block,并建立:
CPU block id -> GPU block id的传输对。
6.6 异步load请求进入WAITING_FOR_REMOTE_KVS
如果load_kv_async=True:
request.status = RequestStatus.WAITING_FOR_REMOTE_KVS
step_skipped_waiting.prepend_request(request)
request.num_computed_tokens = num_computed_tokens
continue逐行解释:
- 请求状态改成
WAITING_FOR_REMOTE_KVS,说明不是普通waiting,而是在等外部KV加载。 - 放入
skipped_waiting,本轮不进running。 request.num_computed_tokens提前设置为“本地+外部命中”的数量,但注释强调:在transfer完成前,不会使用这个值继续计算。- 如果transfer失败,后面会通过
_update_requests_with_invalid_blocks()把这个计数往回调。
6.7 build_connector_meta:调度输出里携带传输计划
本轮scheduler_output构建完成后:
meta = self._build_kv_connector_meta(self.connector, scheduler_output)
scheduler_output.kv_connector_metadata = meta注释写得很清楚,这一步有三个目的:
- plan KV cache store。
- 把所有KV cache load/save操作包装成一个opaque object。
- 清理connector内部状态。
注意这里不是只给异步load用。即使本轮没有远程load,也可能有store计划,例如把刚算完的KV保存到外部cache。
6.8 worker回传后,scheduler如何恢复请求
模型执行结束后,scheduler在_update_from_kv_xfer_finished()里处理KVConnectorOutput。
先让scheduler-side connector处理自己的状态:
if self.connector is not None:
self.connector.update_connector_output(kv_connector_output)然后处理完成接收的请求:
for req_id in kv_connector_output.finished_recving or ():
req = self.requests[req_id]
if req.status == RequestStatus.WAITING_FOR_REMOTE_KVS:
self.finished_recving_kv_req_ids.add(req_id)
else:
assert RequestStatus.is_finished(req.status)
self._free_blocks(self.requests[req_id])解释:
- 如果请求仍在等远端KV,就把id加入
finished_recving_kv_req_ids。 - 如果请求已经结束,说明用户可能abort了请求但KV load后来才完成,这时释放延迟持有的block。
处理完成发送的请求:
for req_id in kv_connector_output.finished_sending or ():
self._free_blocks(self.requests[req_id])这对应request_finished()返回True的情况:请求结束时没有释放block,等send完成后再释放。
6.9 WAITING_FOR_REMOTE_KVS如何重新进入调度
下一次调度时,scheduler会尝试提升blocked waiting request:
if request.status == RequestStatus.WAITING_FOR_REMOTE_KVS:
if request.request_id not in self.finished_recving_kv_req_ids:
return False
self._update_waiting_for_remote_kv(request)
request.status = RequestStatus.WAITING
return True_update_waiting_for_remote_kv()做的事:
- 如果这个请求在失败集合里,根据当前
num_computed_tokens缓存成功部分,或者释放block准备重算。 - 如果没失败,把这些block正式放入prefix cache。
- 如果是full prompt hit,把
num_computed_tokens减1,因为最后一个token需要重算才能采样下一个token。 - 从
finished_recving_kv_req_ids移除请求。
这解释了一个常见疑问:为什么远程KV full hit时还要重算最后一个token?
因为decode要基于最后一个prompt token的输出logits采样下一个token;KV cache只保存attention历史,不等于已经有当前step的采样结果。
6.10 加载失败:fail还是recompute
worker侧如果发现外部KV加载失败,会把block id放到:
KVConnectorOutput.invalid_block_idsscheduler先调用_handle_invalid_blocks()找受影响请求,然后:
kv_load_failure_policy="fail":把请求标成FINISHED_ERROR。kv_load_failure_policy="recompute":把受影响token从“已计算”里扣掉,后续重新调度计算。
这就是为什么connector必须只报告“确实加载失败的block id”,否则可能导致错误重算或错误失败。
7. Worker推理调用链逐行讲解
worker侧主入口在vllm/v1/worker/gpu/kv_connector.py和gpu/model_runner.py。
7.1 Worker初始化:全局KV transfer group
worker初始化KV cache前会调用:
ensure_kv_transfer_initialized(self.vllm_config, kv_cache_config)这个函数在kv_transfer_state.py里:
if vllm_config.kv_transfer_config.is_kv_transfer_instance and _KV_CONNECTOR_AGENT is None:
_KV_CONNECTOR_AGENT = KVConnectorFactory.create_connector(
config=vllm_config,
role=KVConnectorRole.WORKER,
kv_cache_config=kv_cache_config,
)逐行解释:
- 每个worker进程有一个全局
_KV_CONNECTOR_AGENT。 - 只有
kv_transfer_config.is_kv_transfer_instance为真才创建。 - 这里的role是
WORKER。
然后GPUModelRunner初始化KV cache tensor后调用:
self.kv_connector = get_kv_connector(self.vllm_config, kv_caches_dict)如果没有全局KV transfer group,返回NO_OP_KV_CONNECTOR;否则返回ActiveKVConnector。
7.2 ActiveKVConnector初始化:注册KV cache
ActiveKVConnector.__init__()做三件事:
self.kv_connector = get_kv_transfer_group()
self.kv_connector.register_kv_caches(kv_caches_dict)
self.kv_connector.set_host_xfer_buffer_ops(copy_kv_blocks)含义:
- 拿到全局worker-side connector。
- 把每层KV cache tensor注册给connector。
- 把vLLM内置的block copy函数交给connector,供host staging场景使用。
这个注册动作很重要。没有它,connector只知道“block id”,不知道“block id对应哪块tensor内存”。
7.3 forward前:bind metadata、处理抢占、启动load
ActiveKVConnector.pre_forward():
kv_connector_metadata = scheduler_output.kv_connector_metadata
self.kv_connector.bind_connector_metadata(kv_connector_metadata)
self.kv_connector.handle_preemptions(kv_connector_metadata)
self.kv_connector.start_load_kv(get_forward_context())逐行解释:
- 从
scheduler_output拿本轮metadata。 - 绑定到worker-side connector内部。
- 如果本轮有preemption或block即将被覆盖,connector有机会先flush/sync,避免异步store读到被覆盖的数据。
- 调
start_load_kv()启动load。
pre_forward()对full CUDA graph路径和eager/piecewise路径都要调用。对full graph,vLLM在run_fullgraph()之前调用;对eager/piecewise,vLLM在set_forward_context(...)上下文中调用。
7.4 attention层:decorator插入layer级同步和保存
KV connector真正靠近attention的地方是maybe_transfer_kv_layer。
它包在attention入口上:
@maybe_transfer_kv_layer
def unified_attention_with_output(...):
...
self.impl.forward(..., kv_cache, attn_metadata, ...)decorator逻辑:
if not has_kv_transfer_group() or not is_v1_kv_transfer_group():
return func(*args, **kwargs)
layer_name = _resolve_layer_name(...)
attn_metadata, _, kv_cache, _ = get_attention_context(layer_name)
connector = get_kv_transfer_group()
if attn_metadata is None or not connector.has_connector_metadata():
return func(*args, **kwargs)
connector.wait_for_layer_load(layer_name)
result = func(*args, **kwargs)
connector.save_kv_layer(layer_name, kv_cache, attn_metadata)
return result逐行解释:
- 没有KV connector时直接执行attention,零额外行为。
- 不是V1 connector也直接执行。
- 解析
layer_name,因为torch compile/custom op里layer name可能不是普通字符串。 - 从
forward_context拿到当前层的attn_metadata、attention layer对象、KV cache tensor、slot mapping。 - 如果当前没有metadata,说明这轮没有connector工作,也直接执行attention。
- attention前调用
wait_for_layer_load(layer_name)。 - 执行原attention。这个过程中会读写paged KV cache。
- attention后调用
save_kv_layer(layer_name, kv_cache, attn_metadata)。
这就是layer-by-layer connector能够做pipeline的原因:它可以在layer N计算时异步准备layer N+1的KV,也可以在layer N结束后立即保存layer N的KV。
7.5 forward后:等待保存并回传状态
ActiveKVConnector.post_forward():
output = KVConnectorOutput()
if wait_for_save:
self.kv_connector.wait_for_save()
output.finished_sending, output.finished_recving = (
self.kv_connector.get_finished(scheduler_output.finished_req_ids)
)
output.invalid_block_ids = self.kv_connector.get_block_ids_with_load_errors()
output.kv_connector_stats = self.kv_connector.get_kv_connector_stats()
output.kv_cache_events = self.kv_connector.get_kv_connector_kv_cache_events()
output.kv_connector_worker_meta = self.kv_connector.build_connector_worker_meta()
self.kv_connector.clear_connector_metadata()
return output逐行解释:
- 创建空
KVConnectorOutput。 - 默认等待保存完成。某些特殊路径会设置
wait_for_save=False。 - 获取完成send/recv的请求id。
- 获取失败block id。
- 获取connector统计信息。
- 获取KV cache事件。
- 获取worker回传metadata。
- 清理本轮metadata。
- 把output交给scheduler。
如果本轮没有实际模型计算,比如DP padding后所有rank都是0 token,vLLM会走no_forward():
self.pre_forward(scheduler_output)
kv_connector_output = self.post_forward(scheduler_output, wait_for_save=False)这保证了即使没有GPU compute,也能推进异步KV传输状态。
8. KVConnectorOutput:worker如何告诉scheduler发生了什么
vllm/v1/outputs.py里的KVConnectorOutput字段:
finished_sending: set[str] | None = None
finished_recving: set[str] | None = None
kv_connector_stats: KVConnectorStats | None = None
kv_cache_events: KVConnectorKVEvents | None = None
kv_connector_worker_meta: KVConnectorWorkerMetadata | None = None
invalid_block_ids: set[int] = field(default_factory=set)
expected_finished_count: int = 0逐项解释:
finished_sending:请求的异步send/save完成。finished_recving:请求的异步recv/load完成。kv_connector_stats:connector自定义统计,比如NIXL传输延迟、失败次数。kv_cache_events:KV cache事件。kv_connector_worker_meta:worker到scheduler的自定义metadata,比如SimpleCPUOffload用它回报哪些store event完成。invalid_block_ids:加载失败的外部KV block。expected_finished_count:对某些connector,完成通知不是简单按world size聚合,这个字段可调整聚合器预期。
merge()方法会合并多worker输出:
- set字段做union。
- stats调用
aggregate()。 - events调用
merge()。 expected_finished_count要求所有输出一致。
这解释了为什么自定义stats和worker metadata要实现自己的聚合逻辑:vLLM可能有多个worker同时返回connector输出。
9. NixlConnector:P/D disaggregation的典型实现
v0.21.0的NIXL connector拆成:
vllm/distributed/kv_transfer/kv_connector/v1/nixl/connector.py
vllm/distributed/kv_transfer/kv_connector/v1/nixl/scheduler.py
vllm/distributed/kv_transfer/kv_connector/v1/nixl/worker.py
vllm/distributed/kv_transfer/kv_connector/v1/nixl/metadata.py9.1 connector.py:薄门面
NixlConnector继承:
class NixlConnector(KVConnectorBase_V1, SupportsHMA):说明它支持V1 API,也支持HMA多group block。
初始化时:
if role == KVConnectorRole.SCHEDULER:
self.connector_scheduler = NixlConnectorScheduler(...)
self.connector_worker = None
elif role == KVConnectorRole.WORKER:
self.connector_scheduler = None
self.connector_worker = NixlConnectorWorker(...)后面所有scheduler-side方法都只是转发:
def get_num_new_matched_tokens(...):
return self.connector_scheduler.get_num_new_matched_tokens(...)worker-side方法也只是转发:
def start_load_kv(...):
self.connector_worker.start_load_kv(self._connector_metadata)这种写法的好处是:
- scheduler逻辑不依赖NIXL worker内部状态。
- worker逻辑不依赖scheduler队列。
- connector类本身只负责符合vLLM接口。
9.2 NIXL如何决定远程prefill命中
NixlConnectorScheduler.get_num_new_matched_tokens():
params = request.kv_transfer_params
if params is not None and params.get("do_remote_prefill"):
token_ids = request.prompt_token_ids or []
actual = self._mamba_prefill_token_count(len(token_ids))
count = actual - num_computed_tokens
if count > 0:
return count, True
...
return 0, False逐行解释:
- NIXL不是自己查一个全局KV索引,而是看请求里是否携带
kv_transfer_params。 do_remote_prefill=True表示这个请求要从远端prefill worker拉KV。actual通常是prompt长度;Mamba模型有特殊处理,可能要少一个token。count = actual - num_computed_tokens表示除本地已命中token外,还要从远端拉多少token。- 返回
True表示异步加载。
所以NIXL的外部命中来源通常不是“缓存系统查到了prefix”,而是上游P/D协议明确告诉decode侧:prefill侧已经算好了这些block,你可以去拉。
9.3 update_state_after_alloc:建立远端block到本地block的映射
NIXL scheduler侧在update_state_after_alloc()里看kv_transfer_params。
如果do_remote_decode:
self._reqs_in_batch.add(request.request_id)这表示当前请求在prefill侧参与了batch,后续可能需要让decode侧读取。
如果使用host buffer,并且是remote decode:
self._reqs_need_save[request.request_id] = request表示prefill侧需要把新算出的KV先保存到host buffer,供NIXL传输。
如果是do_remote_prefill:
- 检查
remote_block_ids是否存在。 - 检查
remote_engine_id、remote_request_id、remote_host、remote_port是否存在。 - 从
KVCacheBlocks里取本地未hash block ids。 - 记录:
self._reqs_need_recv[request.request_id] = (request, local_block_ids)最后把:
params["do_remote_prefill"] = False防止同一请求重复触发远程拉取。
9.4 build_connector_meta:把recv/save/send计划交给worker
NIXL的build_connector_meta():
meta = NixlConnectorMetadata()
for req_id, (req, block_ids) in self._reqs_need_recv.items():
meta.add_new_req_to_recv(
request_id=req_id,
local_block_ids=block_ids,
kv_transfer_params=req.kv_transfer_params,
)
if self.use_host_buffer:
self._build_save_meta(meta, scheduler_output)
meta.reqs_to_send = self._reqs_need_send
meta.reqs_in_batch = self._reqs_in_batch
meta.reqs_not_processed = self._reqs_not_processed
...
return meta逐行解释:
reqs_to_recv告诉worker:哪些请求要从远端读KV,读到哪些本地block。use_host_buffer时,还要构造save metadata,让worker把本地GPU KV保存到host buffer。reqs_to_send记录prefill侧有哪些请求的block要保留,等decode侧读取。reqs_in_batch和reqs_not_processed用于处理异步调度下请求是否真的进入batch,以及abort场景。- 构造完metadata后,清空scheduler侧暂存集合。
9.5 request_finished:prefill侧如何把remote参数交出去
NIXL的request_finished()在P/D里非常关键。
如果请求没有kv_transfer_params,直接:
return False, None如果还带着do_remote_prefill,说明请求还没调度就结束或abort了。NIXL会放一个空recv任务,避免远端prefill block泄漏。
如果不是do_remote_decode,也直接返回。
如果是remote decode并且请求正常到达长度上限:
delay_free_blocks = any(len(group) > 0 for group in block_ids)
if delay_free_blocks:
self._reqs_need_send[request.request_id] = expiration_time
block_ids = self.get_sw_clipped_blocks(block_ids)
return delay_free_blocks, dict(
do_remote_prefill=True,
do_remote_decode=False,
remote_block_ids=block_ids,
remote_engine_id=self.engine_id,
remote_request_id=request.request_id,
remote_host=self.side_channel_host,
remote_port=self.side_channel_port,
tp_size=...
)这段逻辑含义:
- 如果有实际block,就延迟释放,让decode侧有时间读。
_reqs_need_send记录请求和超时时间。kv_transfer_params返回给上层,decode侧拿它发起remote prefill读取。- 参数里包含远端block ids、远端engine id、远端request id、host、port、TP size。
这就是P/D disaggregation里KV传输参数从prefill侧流向decode侧的地方。
9.6 worker.start_load_kv:真正触发非阻塞NIXL传输
NixlConnectorWorker.start_load_kv():
for req_id, meta in metadata.reqs_to_recv.items():
meta.local_physical_block_ids = self._logical_to_kernel_block_ids(
meta.local_block_ids
)
remote_engine_id = meta.remote.engine_id
self._recving_metadata[req_id] = meta
if remote_engine_id not in self._remote_agents:
self._background_nixl_handshake(req_id, remote_engine_id, meta)
continue
self._read_blocks_for_req(req_id, meta)逐行解释:
- scheduler给的是逻辑block id,worker要转成kernel/物理block id。
- 远端block id保留逻辑形式,后续根据远端engine的block size比例展开。
_recving_metadata保存请求metadata,后续完成、失败、后处理都需要。- 如果还没有远端NIXL agent信息,启动后台handshake。
- 如果已经握手,直接发起异步read。
后面还会处理_ready_requests:握手刚完成的请求也会立即开始read。
9.7 worker.get_finished:完成通知、postprocess和失败block
NIXL worker的get_finished():
done_sending = self._get_new_notifs()
done_recving = self._pop_done_transfers(self._recving_transfers)
done_recving.update(self._failed_recv_reqs)
...
for req_id in done_recving:
meta = self._recving_metadata.pop(req_id, None)
if self.use_host_buffer:
self.sync_recved_kv_to_device(req_id, meta)
...
return done_sending, done_recving逐行解释:
_get_new_notifs()读取远端发来的“已经读完,可以释放”通知,对应finished_sending。_pop_done_transfers()轮询NIXL异步read完成,对应finished_recving。- 失败的recv也要加入
done_recving,因为scheduler必须被唤醒去处理失败。 - 如果使用host buffer,完成后还要把host staging里的KV同步回device KV cache。
- 异构block size或layout场景还要做postprocess。
失败block通过:
get_block_ids_with_load_errors()返回并清空。scheduler据此fail或recompute。
10. SimpleCPUOffloadConnector:本地CPU offload的典型实现
SimpleCPUOffloadConnector适合理解offload connector,因为它比NIXL少了网络握手。
10.1 初始化:scheduler manager和worker handler分离
if role == KVConnectorRole.SCHEDULER:
self.scheduler_manager = SimpleCPUOffloadScheduler(...)
elif role == KVConnectorRole.WORKER:
self.worker_handler = SimpleCPUOffloadWorker(...)如果prefix caching没开,它会warning并禁用CPU offload,因为CPU offload复用的是prefix cache block hash机制。
容量来自:
cpu_bytes_to_use
cpu_bytes_to_use_per_rank其中cpu_bytes_to_use是server-wide,按world size均分;cpu_bytes_to_use_per_rank可以显式覆盖。
10.2 get_num_new_matched_tokens:在CPU block pool里查最长命中
SimpleCPUOffloadScheduler.get_num_new_matched_tokens():
skipped = num_computed_tokens // self.block_size
remaining_hashes = request.block_hashes[skipped:]
max_hit_len = request.num_tokens - 1 - num_computed_tokens
_, hit_length = self.cpu_coordinator.find_longest_cache_hit(
remaining_hashes, max_hit_len
)
if hit_length > 0:
return hit_length, True
return 0, False逐行解释:
- 本地GPU prefix cache已经命中的block跳过。
- 用剩下的block hash去CPU cache里查。
max_hit_len减1,是因为最后一个token仍要重算用于采样。- 命中后返回
True,表示异步从CPU搬回GPU。
10.3 update_state_after_alloc:生成CPU->GPU block copy计划
核心逻辑:
- 根据
num_external_tokens算要load多少block。 - 从CPU block pool找到命中的CPU blocks。
- 从GPU分配结果中找到对应目标GPU block ids。
- touch CPU blocks,避免异步load时被淘汰。
- touch GPU blocks,避免异步load时被释放。
- 写入
_reqs_to_load[req_id] = LoadRequestState(...)。
这个connector展示了scheduler侧connector最典型的职责:不搬数据,只记录“从哪些外部block搬到哪些GPU block”。
10.4 build_connector_meta:store和load一起打包
build_connector_meta()先准备store:
store_gpu, store_cpu, store_req_ids = self.prepare_store_specs(scheduler_output)再准备load:
for req_id, load_state in self._reqs_to_load.items():
load_gpu.extend(load_state.transfer_meta.gpu_block_ids)
load_cpu.extend(load_state.transfer_meta.cpu_block_ids)最后返回:
SimpleCPUOffloadMetadata(
load_event=...,
load_gpu_blocks=...,
load_cpu_blocks=...,
store_event=...,
store_gpu_blocks=...,
store_cpu_blocks=...,
need_flush=bool(scheduler_output.preempted_req_ids),
)这里的event id是scheduler和worker之间对齐异步copy完成状态的编号。
10.5 worker.get_finished:延迟提交copy以隐藏开销
SimpleCPUOffload worker比较特殊:
start_load_kv(): pass
wait_for_layer_load(): pass
save_kv_layer(): pass
wait_for_save(): pass真正提交copy是在get_finished():
if metadata.load_cpu_blocks:
self._backend.launch_copy(..., is_store=False, event_idx=metadata.load_event)
if metadata.store_gpu_blocks:
self._backend.launch_copy(..., is_store=True, event_idx=metadata.store_event)注释说明这么做是为了把CPU侧block copy op开销隐藏到GPU compute之后。然后它轮询CUDA events:
- load event完成后,返回
finished_recving请求id。 - store event完成后,写入
_completed_store_events。 build_connector_worker_meta()把完成的store events回传给scheduler。
10.6 update_connector_output:scheduler确认store真正完成
SimpleCPUOffload scheduler侧处理worker metadata:
meta = connector_output.kv_connector_worker_meta
for event_idx, count in meta.completed_store_events.items():
total = self._store_event_pending_counts.get(event_idx, 0) + count
if total >= self._expected_worker_count:
self._process_store_event(event_idx)含义:
- 多worker场景下,一个store event需要等所有相关worker都完成。
- 完成后把CPU blocks正式插入CPU prefix cache map。
- 释放之前touch住的CPU/GPU block ref count。
这说明“worker说copy完成”和“scheduler把block纳入cache索引”是两个阶段。
11. 同步load与异步load的行为差异
get_num_new_matched_tokens()第二个返回值决定scheduler路径。
11.1 同步load:本轮继续计算
如果返回:
(external_tokens, False)scheduler会:
- 把外部命中计入
num_computed_tokens。 - 继续计算剩余
num_new_tokens。 - 请求进入running batch。
- worker必须在本轮forward前或attention前确保KV已经可用。
这种模式适合很快的本地加载,或者connector在start_load_kv()里同步完成。
11.2 异步load:本轮只发起传输
如果返回:
(external_tokens, True)scheduler会:
- 给外部KV分配目标GPU block。
- 设置
num_new_tokens = 0。 - 请求状态变成
WAITING_FOR_REMOTE_KVS。 - 本轮worker只拿metadata发起传输。
- 传输完成后,下轮再把请求提升回
WAITING继续调度。
这种模式适合远程KV传输和CPU/GPU异步copy,因为可以和其他请求的计算重叠。
12. 自定义connector应该怎么写
最小结构:
class MyConnector(KVConnectorBase_V1, SupportsHMA):
def __init__(self, vllm_config, role, kv_cache_config):
super().__init__(vllm_config, role, kv_cache_config)
if role == KVConnectorRole.SCHEDULER:
...
else:
...必须实现的抽象方法:
- worker侧:
start_load_kv()、wait_for_layer_load()、save_kv_layer()、wait_for_save()。 - scheduler侧:
get_num_new_matched_tokens()、update_state_after_alloc()、build_connector_meta()。 - 如果继承
SupportsHMA:request_finished_all_groups()。
强烈建议实现:
register_kv_caches():拿到worker侧KV tensor。get_finished():上报异步传输完成。get_block_ids_with_load_errors():上报失败block。build_connector_worker_meta()和KVConnectorWorkerMetadata.aggregate():多worker场景同步状态。shutdown():关闭线程、socket、NIXL agent、文件句柄。requires_piecewise_for_cudagraph():如果依赖layer-wise Python hook,避免FULL CUDA graph跳过Python逻辑。
几个常见错误:
- 在
get_num_new_matched_tokens()里做有副作用的状态修改。这个方法可能被重复调用,应该尽量只查询。 - 异步load返回
True但没有touch或保护目标GPU block,导致block被提前复用。 request_finished()返回True后,忘记在get_finished()里返回finished_sending,导致block永远不释放。- worker侧忘记
clear_connector_metadata(),下一轮误用旧metadata。 - 只处理单KV group,在HMA开启时拿错block ids。
- 失败传输没有填
invalid_block_ids,scheduler会把错误KV当作可用KV。
13. 一个完整请求例子
假设请求prompt长度是1024 tokens,block size是16。
本地GPU prefix cache命中前256 tokens,外部CPU/NIXL命中后512 tokens。
调度过程:
num_new_local_computed_tokens = 256
get_num_new_matched_tokens(request, 256) -> (512, True)
num_computed_tokens = 256 + 512 = 768
load_kv_async = True
num_new_tokens = 0
allocate_slots(..., num_external_computed_tokens=512, delay_cache_blocks=True)
update_state_after_alloc(request, blocks, 512)
request.status = WAITING_FOR_REMOTE_KVS
request.num_computed_tokens = 768
build_connector_meta()worker过程:
bind_connector_metadata(meta)
start_load_kv(): CPU->GPU or remote->local GPU async transfer
post_forward/no_forward:
get_finished() -> maybe no completion yet后续某一轮:
get_finished() -> finished_recving={req_id}
scheduler._update_from_kv_xfer_finished()
finished_recving_kv_req_ids.add(req_id)
_try_promote_blocked_waiting_request()
_update_waiting_for_remote_kv()
request.status = WAITING再次调度:
request.num_computed_tokens = 768
num_new_tokens = 1024 - 768 = 256
进入running batch继续prefill最后256 tokens如果1024 tokens全部来自外部KV,scheduler会在load完成后把num_computed_tokens从1024改成1023,让最后一个token重新计算并产生采样logits。
14. 和prefix caching的关系
KV connector和vLLM本地prefix caching不是同一个东西,但它们在调度里被串起来:
local prefix cache hit -> external KV connector hit -> compute remaining tokens本地prefix cache由KVCacheManager.get_computed_blocks()处理,外部cache由connector.get_num_new_matched_tokens()处理。
外部KV加载完成后,scheduler会调用:
self.kv_cache_manager.cache_blocks(request, request.num_computed_tokens)把加载好的block纳入本地prefix cache体系。这样后续请求可能直接本地命中,不再走外部connector。
但要注意:
- 异步load尚未完成时,block不能进入prefix cache。
- load失败时,必须避免把坏block加入cache。
- full hit仍需重算最后一个token。
15. 和CUDA graph的关系
KV connector的layer hook是Python逻辑:
connector.wait_for_layer_load(layer_name)
...
connector.save_kv_layer(layer_name, kv_cache, attn_metadata)如果connector依赖这些hook执行异步同步或保存,而模型forward被FULL CUDA graph捕获,Python hook可能不会在replay时执行,造成数据竞争。
因此KVConnectorBase_V1提供:
requires_piecewise_for_cudagraph(extra_config) -> boolconnector如果需要layer-wise Python操作,应该返回True。vLLM配置检查里会把FULL CUDA graph改成PIECEWISE模式,让图分段执行,中间保留Python hook机会。
16. 实用判断:什么时候用哪类connector
| 场景 | 更适合的connector方向 | 原因 |
|---|---|---|
| 单机GPU显存不足,要把冷KV放CPU | SimpleCPUOffloadConnector或OffloadingConnector |
不需要网络,重点是GPU/CPU block生命周期 |
| P/D disaggregation,跨机器搬KV | NixlConnector、MooncakeConnector |
需要远端metadata、RDMA/UCX/side channel |
| 已经部署LMCache | LMCacheConnectorV1 |
复用LMCache的索引、存储和淘汰策略 |
| 多种后端组合 | MultiConnector |
一个请求可能同时涉及多类KV后端 |
| 只是学习接口 | ExampleConnector |
逻辑简单,但不适合生产 |
使用前要确认四件事:
- 你的模型类型和KV cache layout是否被该connector支持。
- HMA是否开启,以及connector是否实现
SupportsHMA。 - 传输失败时希望
fail还是recompute。 - FULL CUDA graph是否会绕过connector需要的Python hook。
17. 总结
vLLM V1 KV Connector的核心不是“把tensor复制一下”,而是把KV cache传输变成调度器可理解、worker可执行、attention层可同步、失败可恢复的一套协议。
最重要的主线是:
KVTransferConfig
-> KVConnectorFactory创建scheduler/worker双边connector
-> scheduler查询外部命中并分配block
-> build_connector_meta把计划发给worker
-> worker在forward前后执行load/save
-> attention hook做layer级等待和保存
-> KVConnectorOutput回报完成、失败和统计
-> scheduler恢复请求或释放延迟block理解这条链路后,再看NIXL、Mooncake、LMCache、CPU offload这些实现,本质区别就清楚了:它们复用同一套vLLM调度协议,只是外部KV在哪里、如何寻址、如何搬运、何时认为完成不同。
参考
- vLLM GitHub tags:https://github.com/vllm-project/vllm/tags
- vLLM
v0.21.0KVTransferConfig源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/config/kv_transfer.py - vLLM
v0.21.0KVConnectorBase_V1源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/distributed/kv_transfer/kv_connector/v1/base.py - vLLM
v0.21.0KVConnectorFactory源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/distributed/kv_transfer/kv_connector/factory.py - vLLM
v0.21.0V1 Scheduler源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/v1/core/sched/scheduler.py - vLLM
v0.21.0GPU worker KV connector源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/v1/worker/gpu/kv_connector.py - vLLM
v0.21.0attention KV transfer hook源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/model_executor/layers/attention/kv_transfer_utils.py - vLLM
v0.21.0NIXL connector源码:https://github.com/vllm-project/vllm/tree/v0.21.0/vllm/distributed/kv_transfer/kv_connector/v1/nixl - vLLM
v0.21.0Simple CPU Offload connector源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/distributed/kv_transfer/kv_connector/v1/simple_cpu_offload_connector.py - vLLM
v0.21.0KVConnectorOutput源码:https://github.com/vllm-project/vllm/blob/v0.21.0/vllm/v1/outputs.py